
Jeden z pierwszych moich wpisów na blogu dotyczył uczenia maszynowego według wujka Google.
Od tego czasu pojawiły się nowe usługi , które znacznie ułatwiają rozpoczęcie pracy z modelami uczenia maszynowego.
Postanowiłem przybliżyć jedną z usług Microsoftu, którą można przetestować za darmo.
Spróbujmy przygotować model, który potrafi klasyfikować zdjęcia. Na zdjęciach będziemy rozpoznawać różne zwierzęta.
Serwis wymaga zalogowania się na konto Microsoft, ja wykorzystałem swój LiveID.
Po zalogowaniu tworzymy nowy projekt:
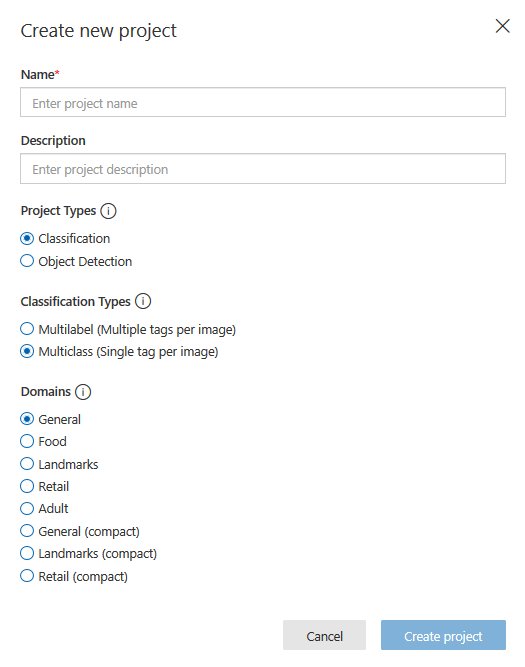
Wypełniamy nazwę projektu, jego opis, projekt typu klasyfikatora (Classification) i typ klasyfikacji (MultiClass). W ten sposób każdy z obrazów będzie otagowany jedną cechą. Jako domenę użyłem (General compact). Ustawienie modelu jako przenośnego będzie ważne dla dalszej części naszej przygody, gdy będziemy eksportować gotowy model.
Jako zbioru treningowego dla trzech kategorii (kot, pies, koń) użyłem zdjęć z poniższych adresów:
a) psy i koty
https://www.floydhub.com/fastai/datasets/cats-vs-dogs/2/train
b) konie:
https://jamie.shotton.org/work/data.html
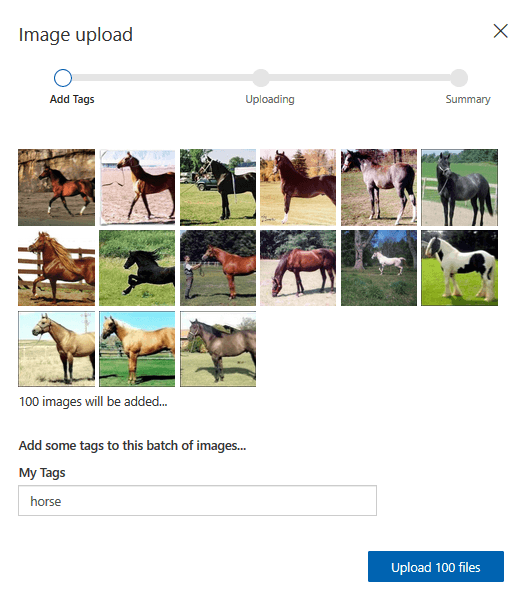
Dla każdego z gatunków zwierząt załadowałem odpowiednio po sto zdjęć. To jest nasz zbiór treningowy, który zawiera trzysta przypadków oznakowanych “cat”, “dog” lub “horse”. Ten zbiór zawiera poprawnie przypisane otagowanie i jest bazą do przygotowania modelu uczenia maszynowego, który będzie potrafił odpowiedzieć na pytanie: Czy na zdjęciu (którego model nie zna, gdyż nie ma go w bazie treningowej) jest widoczny kot, pies, czy koń? Budujemy klasyfikator, który jest jednym z głównych algorytmów uczenia nadzorowanego. To my dostarczamy bazę wiedzy i w niej zawieramy cechę, która jest dla modelu prawdą. 
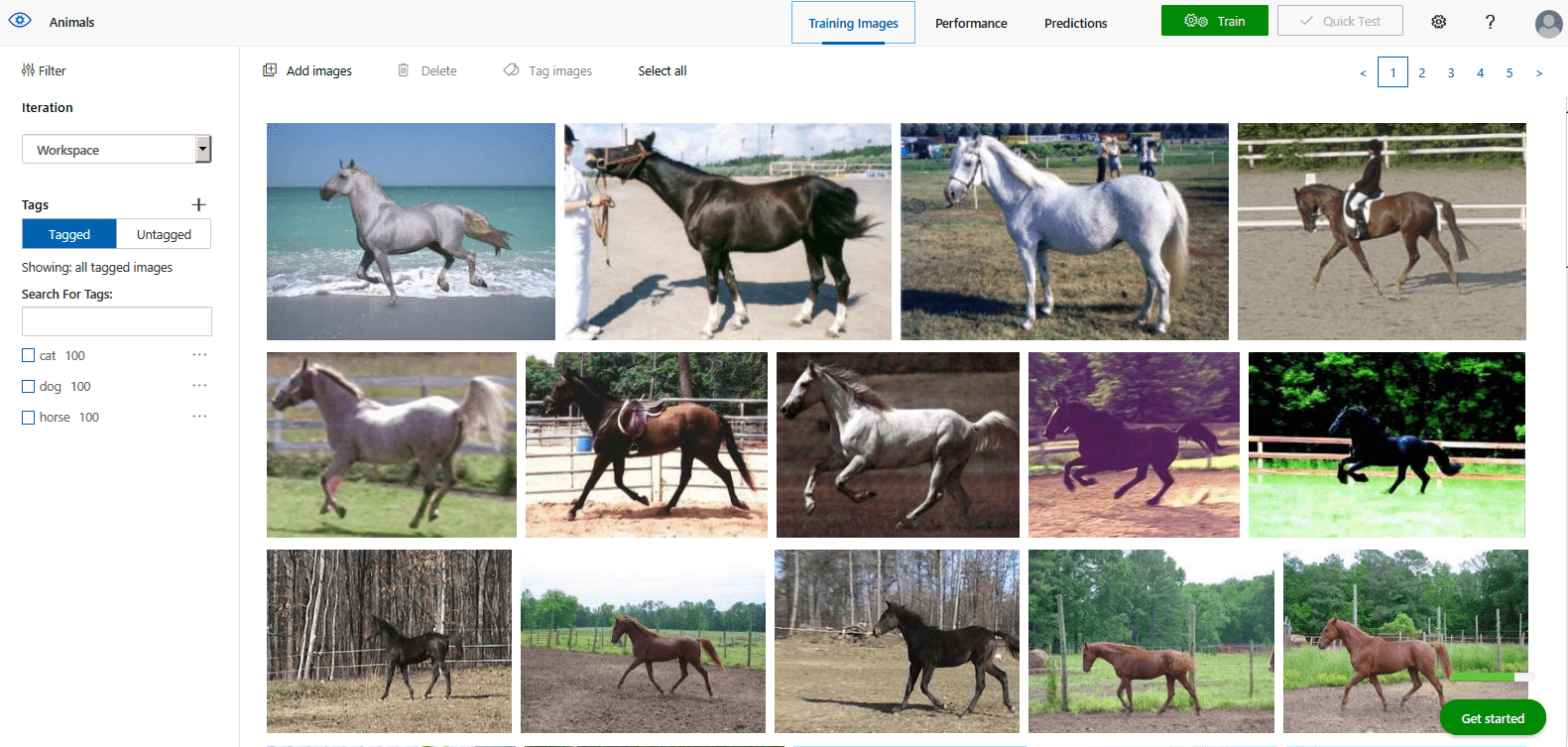
Po załadowaniu wszystkich zdjęć przystępujemy do trenowania danych.
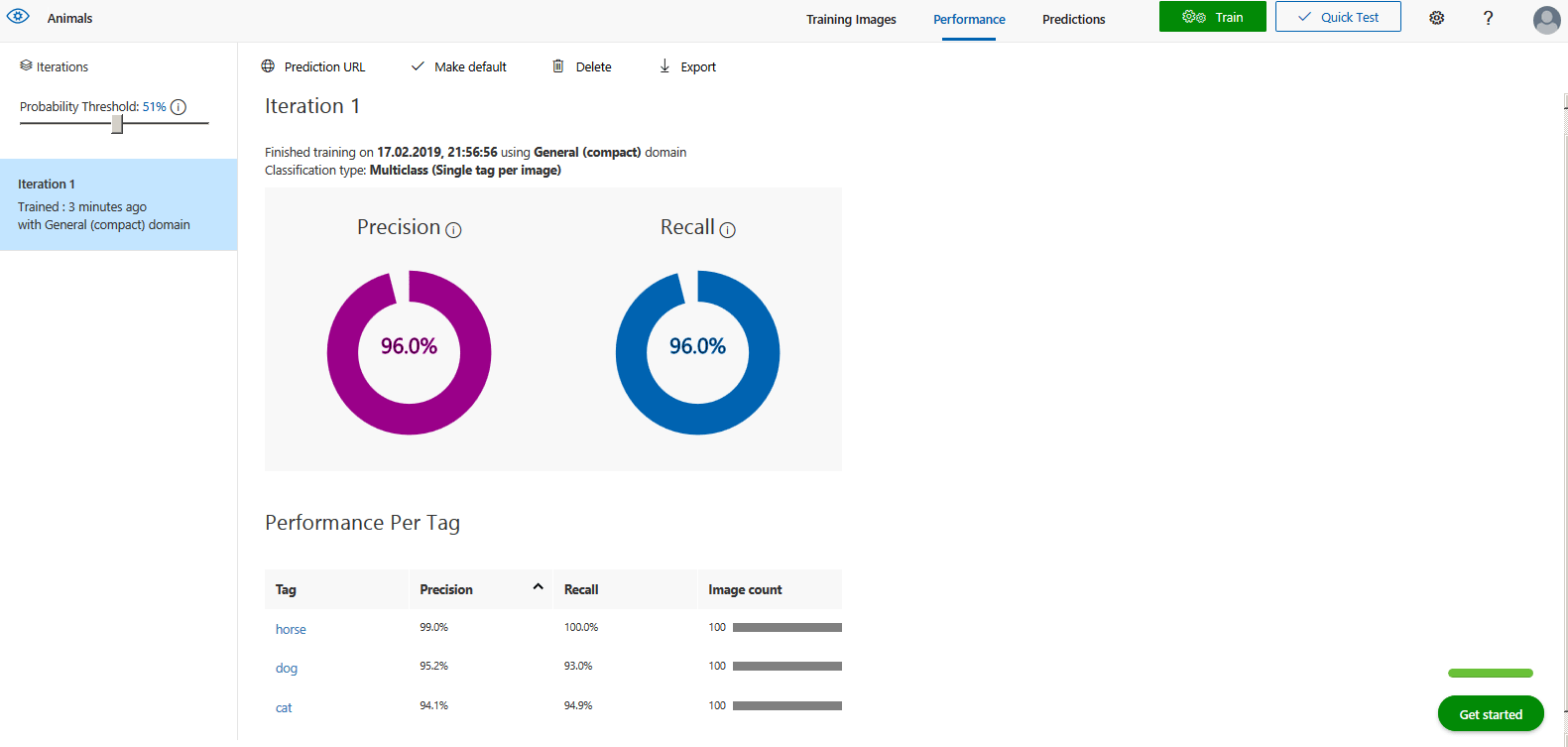
Parametrami tak wytrenowanego modelu są precyzja (precision) i czułość (recall).
Co oznaczają te dwie liczby?
Zacznijmy od tego czym jest macierz pomyłek
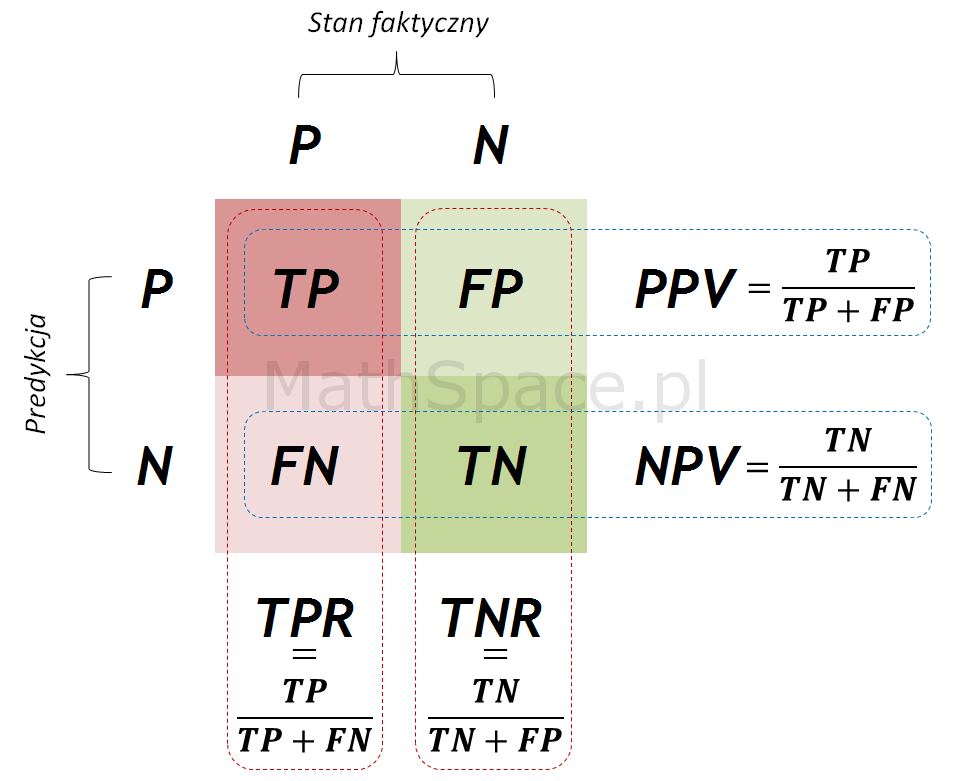
Na obrazie pokazano macierz pomyłek dla modelu uproszczonego do dwóch stanów.
Załóżmy, że na zdjęciu może być kot (prawda, T(rue)) lub nie-kot (fałsz, F(false)). Nasz model predykcyjny wykrywa, tylko te dwa przypadki.
Mamy cztery możliwości:
- Na zdjęciu jest kot, model wykrywa kota, mamy przypadek TP (True Positive)
- Na zdjęciu jest nie-kot, model wykrywa nie-kota, mamy przypadek TN (True Nagative)
- Na zdjęciu jest kot, model wykrywa nie-kota, mamy przypadek FN (False Negative)
- Na zdjęciu jest nie-kot, model wykrywa nie-kota, mamy przypadek FP (False Positive)
Precision (precyzja) to iloraz -> TP/(TP+FP)
Recall (czułość) to iloraz TP/(TP+FN)
Po przygotowaniu wytrenowanego modelu możemy go wyeksportować. Mamy kilka możliwości, możemy zapisać go do rozwoju na urządzeniach mobilnych (iOS lub Android). Najciekawszą opcją jest, moim zdaniem możliwość, która kryje się pod nazwa DF (Dockerfile) .
Model raz nauczony można też w prosty sposób testować na nowych zdjęciach. Te nowe zdjęcia mogą być kolejnym wsadem, który rozbudowuje naszą bazę wiedzy dla danych treningowych. Pamiętajmy, że proces uczenia ma często cykliczny charakter.
 Pobieramy spakowany kod aplikacji w Pythonie, która wykorzystuje jako silnik uczenia maszynowego TensorFlow, serwerem www jest Flask.
Pobieramy spakowany kod aplikacji w Pythonie, która wykorzystuje jako silnik uczenia maszynowego TensorFlow, serwerem www jest Flask.
Częścią takiej aplikacji nie jest żadne ze zdjęć, które były używane w procesie uczenia modelu. Zapisywany jest jedynie plik, który zawiera konfigurację całego modelu zapisanego w formacie danego silnika. W tym przypadku jest to TensorFlow, a plik nosi nazwę model.pb.
Zawartość pliku Dockerfile
FROM python:3.5
ADD app /app
RUN pip install --upgrade pip
RUN pip install -r /app/requirements.txt
# Expose the port
EXPOSE 80
# Set the working directory
WORKDIR /app
# Run the flask server for the endpoints
CMD python app.py
Najważniejsze pliki znajdują się w katalogu app
app.py – główny kod aplikacji
labels.txt – lista możliwych oznaczeń dla zdjęcia
cat
dog
horse
model.pb – zapisane parametry wytrenowanego modelu w TensorFlow
predict.py – kod w Pythonie obsługujący model uczenia maszynowego
requirements.txt – lista modułów, które są potrzebne do działania aplikacji
tensorflow==1.5.0
pillow==5.0.0
numpy==1.14.1
flask==0.12.3
Całość aplikacji umieściłem na moim koncie na Githubie.
Ciekawostką jest to, że po dodaniu projektu do repozytorium pojawia się informacja o potencjalnym problemie z bezpieczeństwem takiej aplikacji:
djkormo,
We found a potential security vulnerability in a repository for which you have been granted security alert access.
| djkormo/ContainersSamples | ||||
| ||||
Trudno, jedna usługa Microsoftu generuje kod, a druga usługa Microsoftu uznaje go za niebezpieczny. Prawdziwa moc synergii.
Po poprawieniu kodu zgodnie z sugestią, komunikat znika.
Przykładowy kod umieściłem w repozytorium githuba.
https://github.com/djkormo/ContainersSamples/tree/master/Docker/customvision-ai-cat-dog-horse-sample
Spróbujmy zbudować z gotowego projektu REST API, które po załadowaniu na wejściu dowolnego zdjęcia, będzie w stanie odpowiedzieć na pytanie, czy znajduje się na nim jedno z trzech gatunków zwierząt.
Wykorzystam do tego darmową piaskownicę
https://labs.play-with-docker.com/

Serwis wymaga założenia konta w publicznym repozytorium DockerHuba.
Po podaniu naszych poświadczeń pojawia się przycisk start

Piaskownica wyłączy się sama po czterech godzinach. Pamiętajmy, aby nie trzymać tam poufnych i wrażliwych danych.
Naciskamy przycisk +Add New Instance i uruchamiany nasz wirtualny kontener.
Na początek klonujemy repozytorium z githuba
git clone https://github.com/djkormo/ContainersSamples.git
Operacja wklejania to skrót klawiszowy Shift+Insert
Operacja kopiowania to skrót klawiszowy Control+Insert
Wchodzimy do odpowiedniego podkatalogu. To repozytorium zawiera też inne aplikacje.
cd ContainersSamples/Docker/customvision-ai-cat-dog-horse-sample/
Zawartość wnętrza tego katalogu
total 8 drwxr-xr-x 5 root root 81 Mar 1 22:03 . drwxr-xr-x 9 root root 210 Mar 1 22:03 .. -rw-r--r-- 1 root root 235 Mar 1 22:03 Dockerfile -rw-r--r-- 1 root root 3056 Mar 1 22:03 README.md drwxr-xr-x 2 root root 96 Mar 1 22:03 app drwxr-xr-x 2 root root 40 Mar 1 22:03 azureml drwxr-xr-x 2 root root 106 Mar 1 22:03 images
Rozpoczynamy proces budowy kontenera.
docker build -t customvision-ai:v1 .
Sending build context to Docker daemon 3.678MB Step 1/7 : FROM python:3.5 3.5: Pulling from library/python 741437d97401: Pull complete .. Digest: sha256:8948474618d373b9b32f991eb325329c54ecb853428a78e80a17842ca81e4b2e Status: Downloaded newer image for python:3.5 ---> 32184312b88b Step 2/7 : ADD app /app ---> 7c6d89055605 Step 3/7 : RUN pip install --upgrade pip ---> Running in 9fd2ee3b58dc Requirement already up-to-date: pip in /usr/local/lib/python3.5/site-packages (19.0.3) Removing intermediate container 9fd2ee3b58dc ---> 150506540dc1 Step 4/7 : RUN pip install -r /app/requirements.txt ---> Running in cc633836f593 .. Step 5/7 : EXPOSE 80 ---> Running in d6a70d77796f Removing intermediate container d6a70d77796f ---> 55299a9bb2ef Step 6/7 : WORKDIR /app ---> Running in d3d4a17ed762 Removing intermediate container d3d4a17ed762 ---> a15cf9bbc7f0 Step 7/7 : CMD python app.py ---> Running in e0be9f571707 Removing intermediate container e0be9f571707 ---> f9d7b0a94eac Successfully built f9d7b0a94eac Successfully tagged customvision-ai:v1
Po krótkiej chwili następuje zbudowanie obrazu aplikacji.
Konfiguracja tego procesu jest zapisana w pliku Dockerfile.
Krótki opis dla osób, które nigdy nie korzystały z technologii konteneryzacji.
Najpierw pobierany jest z repozytorium DockerHub obraz bazowy python:3.5.
FROM python:3.5
Dodawana jest zawartość katalogu app z hosta do katalogu app kontenera
ADD app /app
Instalowana jest aktualizacja oprogramowania do kontroli pakietów w Pythonie.
RUN pip install –upgrade pip
Instalowane są pakiety do Pythona zawarte w pliku requirements.txt.
RUN pip install -r /app/requirements.txt
Port 80 zostaje udostępniony z kontenera do hosta.
EXPOSE 80
Ustalany jest katalog roboczy aplikacji w kontenerze.
WORKDIR /app
Uruchamiane jest polecenie, dzięki któremu powstaje serwer www na udostępnionym wcześniej porcie 80.
CMD python app.py
Po zbudowaniu obrazu możemy uruchomić aplikację
docker run -p 127.0.0.1:33000:80 -d customvision-ai:v1
Podczas uruchamiania aplikacji wskazujemy jej nazwę customvision-ai:v1, mapowaniu portu kontenera (80) na port hosta (33000), flaga -d oznacza odłączenie się od kontenera. Będzie on uruchomiony niejako w tle.
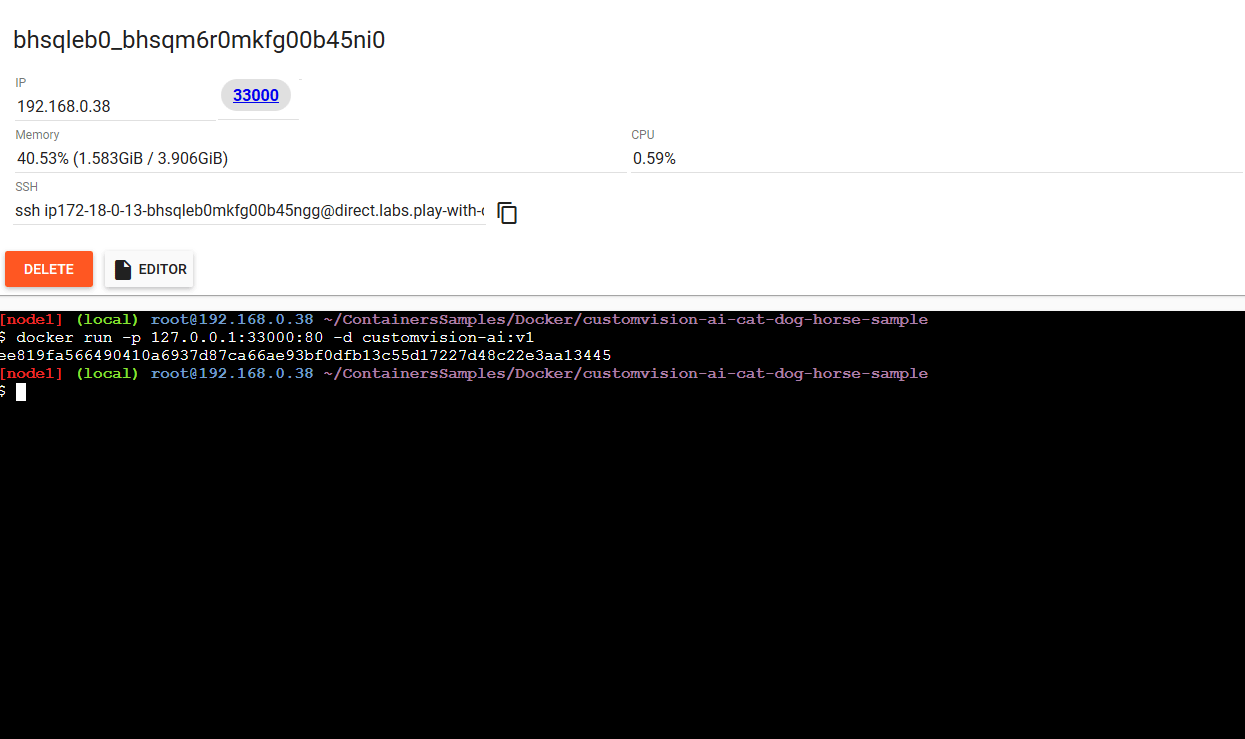
Nad oknem terminala pojawia się port, który został wystawiony po uruchomieniu aplikacji w kontenerze. W naszym przypadku jest to port 33000.
Po uruchomieniu aplikacji możemy sprawdzić, czy usługa działa. Pamiętamy, że aplikacja ma pobrać zdjęcie i określić, czy jest na nim pies, kot czy koń.
W katalogu images umieściłem sześć zdjęć. Żadne z nich nie było wykorzystywane podczas trenowania modelu.
drwxr-xr-x 2 root root 106 Mar 1 22:03 .
drwxr-xr-x 5 root root 81 Mar 1 22:03 ..
-rw-r--r-- 1 root root 82699 Mar 1 22:03 cat1.jpg
-rw-r--r-- 1 root root 40681 Mar 1 22:03 cat2.jpg
-rw-r--r-- 1 root root 73431 Mar 1 22:03 dog1.jpg
-rw-r--r-- 1 root root 394182 Mar 1 22:03 dog2.jpg
-rw-r--r-- 1 root root 31258 Mar 1 22:03 horse1.jpg
-rw-r--r-- 1 root root 104551 Mar 1 22:03 horse2.jpg
Do testowania modelu wykorzystałem polecenie curl. Aplikacja wystawia punkt końcowy (endpoint) pod adresem http://127.0.0.1:33000/image. Wykorzystywany jest POST.
1.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/cat1.jpg
{ "created": "2019-03-01T23:50:13.088601", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 1.0, "tagId": "", "tagName": "cat" } ], "project": "" }
2.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/cat2.jpg
{ "created": "2019-03-01T22:50:35.186215", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 1.0, "tagId": "", "tagName": "cat" } ], "project": "" }
3.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/dog1.jpg
{ "created": "2019-03-01T23:50:56.874340", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 1.0, "tagId": "", "tagName": "dog" } ], "project": "" }
4.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/dog2.jpg
{ "created": "2019-03-01T22:51:21.509273", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 1.0, "tagId": "", "tagName": "dog" } ], "project": "" }
5.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/horse1.jpg
{ "created": "2019-03-01T22:49:21.158930", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 1.0, "tagId": "", "tagName": "dog" } ], "project": "" }
6.
curl -X POST http://127.0.0.1:33000/image -F imageData=@images/horse2.jpg
{ "created": "2019-03-01T22:48:06.126164", "id": "", "iteration": "", "predictions": [ { "boundingBox": null, "probability": 0.0015334499767050147, "tagId": "", "tagName": "dog" }, { "boundingBox": null, "probability": 0.9984666109085083, "tagId": "", "tagName": "horse" } ], "project": "" }
Bystre oko zauważy, że jeden z koni został sklasyfikowany z prawdopodobieństwem 100% jako pies.

Literatura:
https://pl.wikipedia.org/wiki/Tablica_pomy%C5%82ek
https://github.com/djkormo/ContainersSamples/tree/master/Docker/customvision-ai-cat-dog-horse-sample
Mała aktualizacja, wygląda na to że serwis będzie wkrótce zamknięty. Kolejna część o tematyce ML w przygotowaniu

jml
Bardzo fajny wpis, bo pokazuje nie tylko pojedynczą usługę ms, ale całą ścieżkę jak z tego zrobić naszą usługę. Czekam na wpisy o dalszych usługach ze ścieżki AI Engineer. Może analiza sentymentu komentarzy 😉
djkormo
Dziękuję, Jak mawiał klasyk “I’ll will work harder”.
Na razie planowałem rozwój w tym obszarze pokazując różne usługi w Azure, ale nie tylko . Można sobie wyobrazić przygotowanie modelu uczenia głębokiego w Google Colab, gdzie możliwość wykorzystania GPU, a tak wytrenowany model uruchomić w kontenerze wykorzystując orkiestrację w Azure np. AKS. Będzie też wykorzystanie w Azure ACR i ACI.