
Konfiguracja aplikacji na klastrze Kubernetes
W tej części pragnę skupić się nad konfiguracja naszych aplikacji. Dobrą i polecana praktyką jest oddzielenie kodu aplikacji od jej konfiguracji. Jak to wygląda po stronie Kubernetes ?
W jaki sposób możemy przekazywać zmienne środowiskowe ?
Jak podchodzimy do poświadczeń i danych wrażliwych ?
Możemy wstrzykiwać konfigurację w postaci zmiennych środowiskowych jedna zmienna po drugiej. Robiliśmy to w jednym z przykładów dla obrazu postgresql.
Możemy wstrzyknąć cały zbiór zmiennych za pomocą obiektu configmap, ale możemy też podłączyć taki obiekt jako plik konfiguracyjny.
Jeżeli nasze dane konfiguracyjne wymagają większej ochrony (klucze, certyfikaty, hasła) mamy do czynienia z kolejnym typem obiektu jakim jest secret.
Oba typy obiektów pozwalają na reprezentację konfiguracji w postaci par klucz:wartość
Należy pamiętać, iż obiekty configmap nie nadają się do składowania dużej liczby danych, takie należy przechowywać w wolumenach. O tym będzie osobny odcinek.
Zarówno obiekty configmap i secret mogą wyć wykorzystywane przez obiekt pod w dwóch trybach
- zmienne środowiskowe
- wolumeny
Poniższy rysunek pokazuje możliwe schematy.
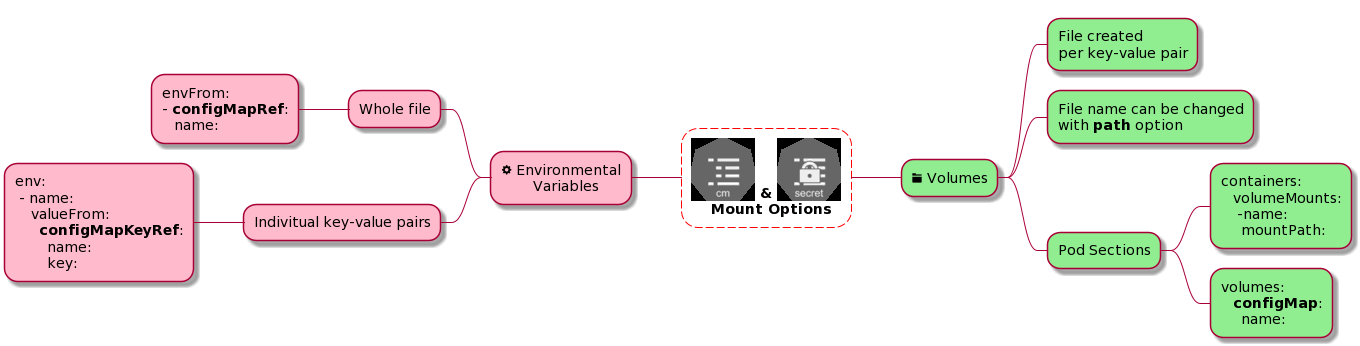
W dzisiejszym odcinku, chciałbym skupić się na lewej (czerwonej) stronie i poćwiczyć wykorzystanie obiektów configmap i secret przez zmienne środowiskowe, z tym, że dla obiektu secret zamiast configMapRef i configMapKeyRef będzie odpowiednio secretRef i secretKeyRef.
Montowanie przez wolumen będzie opisane w jednym z kolejnych części przy okazji ćwiczeń z wolumenami.
Wykorzystamy dwa polecenia kubectl create configmap i kubectl create secret.
Rozpoczynamy część praktyczną.
Wszystkie zasoby w poniższych zadaniach należy umieścić w przestrzeni nazw beta. Jeśli taka nie istnieje na klastrze należy ją utworzyć.
Polecam zawsze dodawanie tej przestrzeni nazw w pliku z manifestem
Zadanie pierwsze
Utwórz obiekt pod na nazwie postgresql-env oparty o obraz postgres:12.4 pracujący na porcie 5432. Dodaj do definicji trzy zmienne środowiskowe
Obiekt należy umieścić w przestrzeni nazw beta.
Przypomnijmy sobie jak to robiliśmy w poprzedniej części.
kubectl run postgresql-env --image=postgres:12.4 --port 5432 \ --env="POSTGRES_DB=postgresdb" --env="POSTGRES_USER=postgresadmin" --env="POSTGRES_PASSWORD=admin123" \ -o yaml --dry-run=client > 01.pod.postgresql-env.yaml
Manifest powinien wyglądać tak:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: postgresql-env
name: postgresql-env
namespace: beta
spec:
containers:
- env:
- name: POSTGRES_DB
value: postgresdb
- name: POSTGRES_USER
value: postgresadmin
- name: POSTGRES_PASSWORD
value: admin123
image: postgres:12.4
name: postgresql-env
ports:
- containerPort: 5432
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: AlwaysWidać, że zmienne środowiskowe realizowane są za pomocą listy, które zawiera w sobie kolejne listy o nazwach name i value. Listy takie są mapami YAML.
Zadanie drugie
Utwórz obiekt typu configmap o nazwie postgresql-configmap, które zawiera następujące pary klucz:wartość
Jak rozpocząć pracę? Najlepiej od przejrzenia pomocy
kubectl create configmap --help
W zwróconej informacji mamy sporo gotowych przykładów użycia
Create a configmap based on a file, directory, or specified literal value.
A single configmap may package one or more key/value pairs.
When creating a configmap based on a file, the key will default to the basename of the file, and the value will default
to the file content. If the basename is an invalid key, you may specify an alternate key.
When creating a configmap based on a directory, each file whose basename is a valid key in the directory will be
packaged into the configmap. Any directory entries except regular files are ignored (e.g. subdirectories, symlinks,
devices, pipes, etc).
Aliases:
configmap, cm
Examples:
# Create a new configmap named my-config based on folder bar
kubectl create configmap my-config --from-file=path/to/bar
# Create a new configmap named my-config with specified keys instead of file basenames on disk
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# Create a new configmap named my-config with key1=config1 and key2=config2
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
# Create a new configmap named my-config from the key=value pairs in the file
kubectl create configmap my-config --from-file=path/to/bar
# Create a new configmap named my-config from an env file
kubectl create configmap my-config --from-env-file=path/to/bar.env
Options:
--allow-missing-template-keys=true: If true, ignore any errors in templates when a field or map key is missing in
the template. Only applies to golang and jsonpath output formats.
--append-hash=false: Append a hash of the configmap to its name.
--dry-run='none': Must be "none", "server", or "client". If client strategy, only print the object that would be
sent, without sending it. If server strategy, submit server-side request without persisting the resource.
--from-env-file='': Specify the path to a file to read lines of key=val pairs to create a configmap (i.e. a Docker
.env file).
--from-file=[]: Key file can be specified using its file path, in which case file basename will be used as
configmap key, or optionally with a key and file path, in which case the given key will be used. Specifying a directory
will iterate each named file in the directory whose basename is a valid configmap key.
--from-literal=[]: Specify a key and literal value to insert in configmap (i.e. mykey=somevalue)
-o, --output='': Output format. One of:
json|yaml|name|go-template|go-template-file|template|templatefile|jsonpath|jsonpath-file.
--save-config=false: If true, the configuration of current object will be saved in its annotation. Otherwise, the
annotation will be unchanged. This flag is useful when you want to perform kubectl apply on this object in the future.
--template='': Template string or path to template file to use when -o=go-template, -o=go-template-file. The
template format is golang templates [http://golang.org/pkg/text/template/#pkg-overview].
--validate=true: If true, use a schema to validate the input before sending it
To co nas interesuje, to przekazanie z linii komend wielokrotnie –from-literal=KEY=VALUE. W manifeście YAML zostanie to zamienione na listę par w postaci map KEY: VALUE.
kubectl create configmap postgresql-configmap --from-literal="POSTGRES_DB=postgresdb" --from-literal="POSTGRES_USER=postgresadmin" --from-literal="POSTGRES_PASSWORD=admin123" -n beta -o yaml --dry-run=client > 02.configmap.postgresql-configmap.yaml
W ten sposób otrzymujemy plik 02.configmap.postgresql-configmap.yaml o zawartości
apiVersion: v1 data: POSTGRES_DB: postgresdb POSTGRES_PASSWORD: admin123 POSTGRES_USER: postgresadmin kind: ConfigMap metadata: creationTimestamp: null name: postgresql-configmap namespace: beta
Warto zwrócić uwagę, iż podstawowa budowa takiego obiektu jest zbliżona do obiektu pod, z tym, że zamiast spec: mamy data:.
W części data: umieszczone są pary klucz: wartość. W poniższym przykładzie
apiVersion: v1 kind: ConfigMap metadata: name: test-configmap data: KEY: VALUE
Warto dodać brakującą mapę namespace: beta w obszarze metadata.
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 02.configmap.postgresql-configmap.yaml
Zadanie trzecie
Utwórz obiekt typu pod o nazwie postgresql-cm oparty o obraz postgres:12.4 pracujący na porcie 5432 i wykorzystujący obiekt configmap o nazwie postgresql-configmap z zadania drugiego.
Na początku możemy skorzystać z przygotowanego manifestu w zadaniu pierwszym. Jest to jedna z prostych sztuczke, które pozwalają zwiększyć tempo rozwiązywania zadań.
cp 01.pod.postgresql-env.yaml 03.pod.postgresql-cm.yaml
Ponieważ chcemy wykorzystać wszystkie zmienne zawarte w obiekcie configmap
zamieniamy:
spec:
containers:
- env:
- name: POSTGRES_DB
value: postgresdb
- name: POSTGRES_USER
value: postgresadmin
- name: POSTGRES_PASSWORD
value: admin123
na:
spec:
containers:
- envFrom:
- configMapRef:
name: postgresql-configmap
Pamiętając oczywiście o zmianie nazwy obiektu. Manifest powinien wyglądać tak
apiVersion: v1
kind: Pod
metadata:
labels:
run: postgresql-cm
name: postgresql-cm
namespace: beta
spec:
containers:
- envFrom:
- configMapRef:
name: postgresql-configmap
image: postgres:12.4
name: postgresql-cm
ports:
- containerPort: 5432
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 03.pod.postgresql-cm.yaml
Zadanie czwarte
Utwórz obiekt typu configmap o nazwie postgresql-configmap-nopass, które zawiera następujące pary klucz:wartość
kubectl create configmap postgresql-configmap-nopass --from-literal="POSTGRES_DB=postgresdb" --from-literal=POSTGRES_USER=postgresadmin -n beta -o yaml --dry-run=client > 04.configmap.postgresql-configmap-nopass.yaml
Ale można też skopiować wygenerowany w zadaniu dwa manifest
cp 02.configmap.postgresql-configmap.yaml 04.configmap.postgresql-configmap-nopass.yaml
Pamiętajmy o usunięciu zbędnej pary zawierającej hasło do bazy i zmianie nazwy obiektu configmap. Bez zmiany nazwy możemy sobie nadpisać obiekt na klastrze, ale ponieważ trzymamy je wszystkie w postaci plików, łatwo można taka pomyłkę naprawić.
Niezależnie od rozwiązania powinniśmy otrzymać plik 04.configmap.postgresql-configmap-nopass.yaml o poniższej zawartości
apiVersion: v1 data: POSTGRES_DB: postgresdb POSTGRES_USER: postgresadmin kind: ConfigMap metadata: creationTimestamp: null name: postgresql-configmap-nopass namespace: beta
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 04.configmap.postgresql-configmap-nopass.yaml
Zadanie piąte
Utwórz obiekt typu secret o nazwie postgresql-secret, które zawiera następujące pary klucz:wartość
kubectl create secret generic postgresql-secret -n beta --from-literal="POSTGRES_PASSWORD=admin123" -o yaml --dry-run=client > 05.secret.postgresql-secret.yaml
Zasadnicza składnia jest identyczna z tą wykorzystującą obiekt configmap, z tym że należy podać przed nazwa obiekty jego typ. W naszym przypadku jest to typ ogólny (generic)
kubectl create secret --help
Mamy trzy możliwości do wyboru
Create a secret using specified subcommand. Available Commands: docker-registry Create a secret for use with a Docker registry generic Create a secret from a local file, directory or literal value tls Create a TLS secret Usage: kubectl create secret [flags] [options]
Druga rzecz, na którą należy zwrócić uwagę, to zakodowaną wartość i niezakodowany klucz.
apiVersion: v1 data: POSTGRES_PASSWORD: YWRtaW4xMjM= kind: Secret metadata: creationTimestamp: null name: postgresql-secret namespace: beta
W jaki sposób można odkodować to hasło ?
Bardzo prostu, gdyż wykorzystany tu został base64.
echo -n admin123 | base64
zwróci nam wartość YWRtaW4xMjM=
Odwrotnie polecenie
echo -n YWRtaW4xMjM= | base64 --decodezwraca nam wartość admin123
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 05.secret.postgresql-secret.yaml
W tym miejscu warto zweryfikować, czy da się odkodować hasło bez wykorzystywania base64 –decode?
Dla polecenia
kubectl describe secret postgresql-secret -n beta
zwracany jest
Name: postgresql-secret Namespace: beta Labels: Annotations: Type: Opaque Data ==== POSTGRES_PASSWORD: 8 bytes
Hasła nie widać, nawet w postaci zakodowanej
Można spróbować pobrać postać w wersji YAML (-o yaml)
kubectl get secret postgresql-secret -n beta -o yaml
W zwróconej postaci widzimy hasło zakodowane.
kubectl get secret postgresql-secret -n beta -o yaml apiVersion: v1 data: POSTGRES_PASSWORD: YWRtaW4xMjM= kind: Secret metadata: name: postgresql-secret namespace: beta type: Opaque
W powyższym manifeście obiektu wdrożonego na klastrze pozbyłem się części doklejanych przez klaster. To dobre ćwiczenie, dla osób, które chcą oglądać postać YAML nie z kodu źródłowego, ale z tego co jest wdrożone. ManagedFields będą się wam śniły nie raz (!).
Istnieje też oprocz kubectl describe secret, czy kubectl get secret -o yaml możliwość skorzystania z jsonpath, czyli takiego sql dla json.
kubectl get secret postgresql-secret -n beta -o jsonpath='{.data}'zwrócony rezultat
{"POSTGRES_PASSWORD":"YWRtaW4xMjM="}
kubectl get secret postgresql-secret -n beta -o jsonpath='{.data.POSTGRES_PASSWORD}'
zwrócony rezultat
YWRtaW4xMjM=
kubectl get secret postgresql-secret -n beta -o jsonpath='{.data.POSTGRES_PASSWORD}' | base64 --decodezwrócony rezultat
admin123
Specyfikację można przejrzeć tutaj
https://kubernetes.io/docs/reference/kubectl/jsonpath/
Zadanie szóste
Utwórz obiekt typu pod o nazwie postgresql-cm-secret oparty o obraz postgres:12.4 pracujący na porcie 5432 i wykorzystujący obiekt configmap o nazwie postgresql-configmap-nopass z zadania czwartego i obiekt secret o nazwie postgresql-secret z zadania piątego.
Obiekt należy umieścić w przestrzeni nazw beta.
Na początku możemy skopiować obiekt pod z zadania drugiego. Podczas generowania na egzaminie kolejnych plików kopiowanie z inneych zadań jest częstą praktyką.
cp 02.pod.postgresql-cm.yaml 06.pod.postgresql-cm-secret.yaml
W manifeście należy dodać jako źródło zmiennych kolejny element listy obiekt secret o nazwie postgresql-secret
- envFrom:
- secretRef:
name: postgresql-secretJak widać zamiast configMapRef mamy secretRef.
Nasz plik z namifestem powinien wyglądać tak
apiVersion: v1
kind: Pod
metadata:
labels:
run: postgresql-cm-secret
name: postgresql-cm-secret
namespace: beta
spec:
containers:
- envFrom:
- configMapRef:
name: postgresql-configmap-nopass
- secretRef:
name: postgresql-secret
image: postgres:12.4
name: postgresql-cm-secret
ports:
- containerPort: 5432
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 06.pod.postgresql-cm-secret.yaml
Zadanie siódme
Utwórz obiekt typu pod o nazwie postgresql-cm-nopass-secret oparty o obraz postgres:12.4 pracujący na porcie 5432 i wykorzystujący obiekt configmap o nazwie postgresql-configmap z zadania drugiego i obiekt secret o nazwie postgresql-secret z zadania piątego.
Z obiektu configmap wykorzystaj tylko dwie zmienne
Obiekt należy umieścić w przestrzeni nazw beta.
Ponieważ zadanie to wygląda bardzo podobnie do zadania szóstego zacznijmy pracę od sklonowania pliku manifest
cp 06.pod.postgresql-cm-secret.yaml 07.pod.postgresql-cm-nopass-secret.yaml
W tak przygotowanym pliku 07.pod.postgresql-cm-nopass-secret.yaml należy zmienić jak zwykle nazwę obiektu
oraz zamienić
- envFrom:
- configMapRef:
name: postgresql-configmap-nopassna:
- env: - name: POSTGRES_DB valueFrom: configMapKeyRef: name: postgresql-configmap key: POSTGRES_DB - name: POSTGRES_USER valueFrom: configMapKeyRef: name: postgresql-configmap key: POSTGRES_USER
Nasz docelowy manifest powinien wyglądać tak:
apiVersion: v1
kind: Pod
metadata:
labels:
run: postgresql-cm-nopass-secret
name: postgresql-cm-nopass-secret
namespace: beta
spec:
containers:
- envFrom:
- secretRef:
name: postgresql-secret
env:
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgresql-configmap
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: postgresql-configmap
key: POSTGRES_USER
image: postgres:12.4
name: postgresql-cm-secret
ports:
- containerPort: 5432
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: AlwaysUważni zauważą brak – przed env. Jest to kolejny element listy (envFrom,env,image,name,ports….). Tylko element pierwszy powinien byc tak oznaczony.
Czy można np. zamienić envFrom z env ? Można. Taki manifest wygląda wtedy tak.
apiVersion: v1
kind: Pod
metadata:
labels:
run: postgresql-cm-nopass-secret
name: postgresql-cm-nopass-secret
namespace: beta
spec:
containers:
- env:
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgresql-configmap
key: POSTGRES_DB
- name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: postgresql-configmap
key: POSTGRES_USER
envFrom:
- secretRef:
name: postgresql-secret
image: postgres:12.4
name: postgresql-cm-secret
ports:
- containerPort: 5432
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
Inne elementy listy rownież mogą mieć zamienioną kolejność. Jest to jedna z cech manifestów YAML dla Kubernetes, która na początku sprawiała mi trudności. Dobrze jest przyjąć konwencję, w której na przyklad pierwszym elementem listy jest name.
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 07.pod.postgresql-cm-nopass-secret.yaml
Zadanie ósme
Utwórz obiekt typu service o nazwie postgresql-webservice, który wystawi obiekt pod o nazwie postgresql-cm-secret z zadania szóstego. Rodzaj serwisu to ClusterIP.
kubectl expose pod/postgresql-cm-secret --name=postgresql-webservice -n beta-o yaml --dry-run=client > 08.service.postgresql-webservice.yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
run: postgresql-cm-secret
name: postgresql-webservice
namespace: beta
spec:
ports:
- port: 5432
protocol: TCP
targetPort: 5432
selector:
run: postgresql-cm-secret
status:
loadBalancer: {}
Tak przygotowany manifest możemy wdrożyć na klaster
kubectl apply -f 08.service.postgresql-webservice.yaml
Na tym etapie zarysowaliśmy jedynie możliwości wstrzykiwania konfiguracji za pomocą zmiennych środowiskowym. W dalszych częsciach postaram się ten temat jeszcze rozszerzyć.
Dla tych, którzy zdążyli się pogubć małe podsumowanie tego co znajduje się w manifeście każdego obiektu umieszczanego w przestrzeni nazw.
Interesuje nas część metadata:
Główne atrybuty, z którymi się spotkamy to
- name
- nemaspace
- labels
- annotations
Przykładowy kawałek menifestu
apiVersion: v1
kind: ConfigMap
# metadata start
metadata:
name: pod-config
namespace: epsilon
labels:
tier: frontend
env: dev
version: 1.8
annotations:
controlled-by: me
# metadata end
Nazwa (name) jest obligatoryjnym atrybutem, który musi być ustawiony podczas tworzenia, czy modyfikacji takich obiektów jak Pod,Deployment, ConfigMap, itp… Nazwa jest dla danej przestrzeni nazw unikalna. Nie uda się wdrożyć dwóch obiektów pod o tej samej nazwie w tej samej przestrzeni.
Każdy obiekt, którego zasięg jest w zakresie przestrzeni nazw, może mieć dodany atrybut namespace. Jeśli nie zostanie podany domyślną wartościa jest przestrzeń nazw default.
Etykliety (labels) są parami klucz:wartość. Są one wykorzystywane do łatywej identyfikacji zasobu, mogą się zmieniać w czasie. Każdy klucz jest unikalny w ramach obiektu.
Adnotacje (annotations) pozwalają na dodanie do obiektu informacji, które nie służą do identyfikacji, ale na przykład do dodatkowej konfiguracji. Jest to powszechnie stosowane przy obiekcie typu ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: basic-ingress
annotations:
kubernetes.io/ingress.global-static-ip-name: "web-static-ip"
spec:
backend:
serviceName: web
servicePort: 8080
I to by było tyle na dziś.
Poprzednie części:
Certified Kubernetes Administrator (CKA) krok po kroku – część 1
Certified Kubernetes Administrator (CKA) krok po kroku – część 2
Następne części
Certified Kubernetes Administrator (CKA) krok po kroku – część 4
Literatura:
https://www.katacoda.com/djkormo/scenarios/kubernetes-cka-part2
https://itnext.io/kubernetes-explained-deep-enough-configuration-cd4a9d1d8dcd
https://kubernetes.io/docs/concepts/configuration/secret/
https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/
https://kubernetes.io/docs/tasks/inject-data-application/distribute-credentials-secure/
https://kubernetes.io/docs/reference/kubectl/jsonpath/
Dodaj komentarz