
Pody statyczne (static pods), kube-scheduler i kontrola rozmieszczenia obiektów pod na węzłach klastra.
Architektura
Czy istnieje możliwość uruchamiania obiektów pod tylko na jedynym węźle klastra ? Czy można wyznaczyć, na którym węźle zostanie uruchomiona nasza mikrousługa ? A może chcemy, by usługi były od siebie odseparowane albo były uruchamiane jak najbliżej siebie ?
Co jest odpowiedzialne za kontrolę takiej konfiguracji. Wszelkie klastry Kubernetes z jakimi mamy do czynienia na egzaminie są instalowane za pomocą narzędzia kubeadm.
Na początku warto przypomnieć sobie architekturę Kubernetes z lotu ptaka
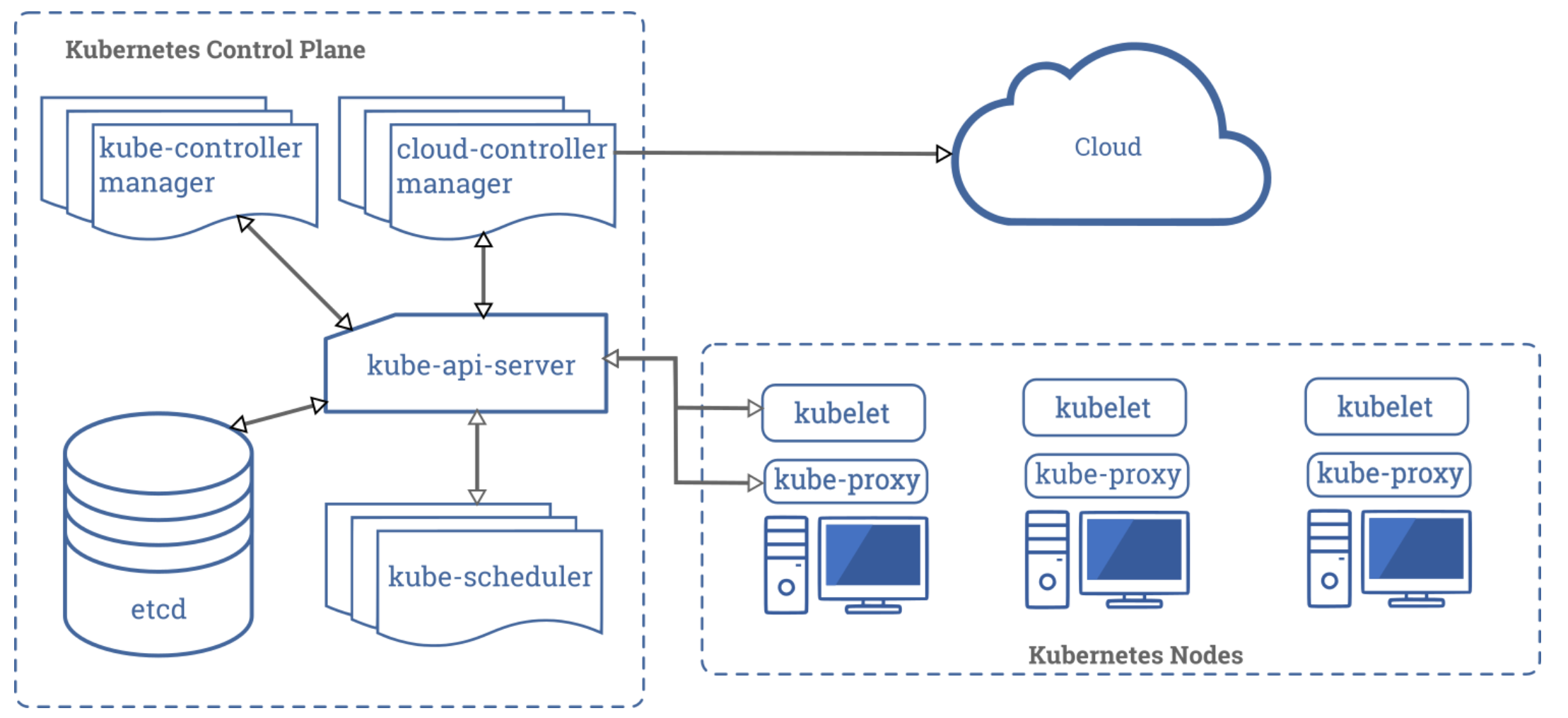
Po lewej stronie mamy wyszczególnione komponenty control-plane (dawniej master) . Etcd, kube-controller-manager i kube-api-server i kube-scheduler są dostarczane w postaci kontenerów. Po prawej stronie mamy komponenty, które są składową węzłów typu worker. Wszelkie komponenty control-plane, oprócz kubelet, który jest plikiem binarnym odpowiedzialnym za tworzenie i kontrolę kontenerów na danym węźle, są w tym rozwiązaniu dostarczane w postaci skonteneryzowanej.
Patrząc literalnie na powyższy obraz można dojść do wniosku ze control-plane nie zawiera kubelet i kube-proxy. Nic bardziej błędnego. Węzeł kontrolny może pełnić rolę węzła typu worker. Tak działa np. popularny minikube. Ale taka konfiguracja nie jest stosowana produkcyjnie, gdzie raczej separujemy części systemowe od aplikacji biznesowych.
Klaster Kubernetes komunikuje się ze światem zewnętrznym przez komponent API-Server.
Przykład wdrożenia nowego obiektu pod na klastrze, pochodzi on z bloga heptio i doskonale pokazuje interakcję między komponentami klastra.

Scheduler w Kubernetes jest niezależnym komponentem, co więcej może być ich więcej niż jeden w danym klastrze. W manifeście obiektu można podać nazwę schedulera, który ma przeprowadzić cały proces wyznaczenia właściwego węzła.
Opiszmy jak działa po kolei w bardzo uproszczony sposób:
Kiedy tworzymy nowy obiekt typu pod jego manifest jest wysyłany do API-server i zapisany przez niego w bazie etcd
Scheduler odpytuje cyklicznie API-Server, czy istnieją obiekty pod, dla których nie określono nazwy węzła. Obiekty takie trafiają do kolejki.
Scheduler pobiera definicję takiego poda i rozpoczyna proces wyznaczenia węzła, na który ma on trafić.
Proces taki składa się z dwóch głównych kroków
a) filtrowania (filter). W tym miejscu wywoływana jest grupa funkcji przyjmujących jako argumenty identyfikator obiektu pod i identyfikator węzła. Funkcje takie zwracają dla danej pary tylko wartości prawdy lub fałszu.
b) punktacja (scoring) W tym miejscu wywoływana jest grupa funkcji przyjmujących jako argumenty identyfikator obiektu pod i identyfikator węzła. Funkcje takie zwracają ranking dla danej pary w postaci liczby.
Na końcu wybierany jest węzeł, dla którego udało się ustalić dopasowanie z największą punktacją.
Wysłany jest komunikat do API-Server,który to jest węzeł. API-Server zleca ustawienie w etcd pod.Spec.NodeName
Kubelet danego węzła zabiera się do pracy, tworzy i kontroluje mikrousługę i raportuje zwrotnie do API-Server o statusie swojej pracy.
Api-Server zleca zapis konfiguracji do bazy etcd.
To co należy zapamiętać.
- Jedynym komponentem klastra komunikującym się z etcd jest API-Server.
- Jedynym komponentem systemowym klastra, który przechowuje stan jest baza danych etcd.
- Jedynym komponentem klastra, który nie może być skonteneryzowany jest kubelet.
Ten ostatni jest odpowiedzialny za komunikację z silnikiem konteneryzacji, którym nie musi być docker, ale np containerd lub cri-o. Kubelet kontroluje stan mikrousług, które utworzył, weryfikuje na bieżąco wykorzystanie zasobów i w razie potrzeby restartuje je.
https://www.tutorialworks.com/difference-docker-containerd-runc-crio-oci/
Nie wszystkie obiekty wdrażane na klastrze Kubernetes korzystają z kube-scheduler. Pomówmy o dwóch przypadkach
- Obiekt kontrolujący obiety pod typu daemonset
- Pody kontrolowane przez kubelet danego węzła, czyli pody statyczne (static pods)
Obiekt daemonset stara się wdrożyć na klastrze stan, w którym na każdym węźle pojawi się dokładnie jedna instancja obiektu pod.
Jeżeli chcemy wdrożyć te obiekty również na węzłach control-plane, to należy dodać w manifeście tolerancję
spec:
template:
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoScheduleOmówimy to dokładniej w części praktycznej
Kubelet
Zobaczmy stan usługi kubelet na dowolnym węźle (control-plane czy worker). Podczas egzaminu mamy do czynienia z dystrybucją Ubuntu i klastrami Kubernetes zainstalowanymi za pomocą narzędzie kubeadm. Takie klastry mają zainstalowane komponenty systemowe w postaci static pods.
systemctl status kubelet
Przykładowy rezultat
● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled) Drop-In: /etc/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: active (running) since Fri 2021-06-04 10:52:09 UTC; 1min 25s ago Docs: https://kubernetes.io/docs/home/ Main PID: 6842 (kubelet) Tasks: 15 (limit: 2336)
Jeśli stan nie jest active to mamy problem i taki węzeł jest traktowany przez klaster jako notReady. To tyle tytułem wstępu do troubleshooting.
Jeśli chcemy się więcej dowiedzieć o problemach z kubelet, możemy skorzystać journactl.
journalctl -u kubelet
Przykładowe logi
-- Logs begin at Fri 2021-06-04 10:50:32 UTC, end at Fri 2021-06-04 10:54:42 UTC. -- Jun 04 10:50:32 controlplane systemd[1]: Started kubelet: The Kubernetes Node Agent. Jun 04 10:50:33 controlplane kubelet[396]: F0604 10:50:33.828046 396 server.go:199] failed to load Kubelet c Jun 04 10:50:33 controlplane systemd[1]: kubelet.service: Main process exited, code=exited, status=255/n/a Jun 04 10:50:33 controlplane systemd[1]: kubelet.service: Failed with result 'exit-code'. Jun 04 10:50:35 controlplane systemd[1]: Stopped kubelet: The Kubernetes Node Agent. Jun 04 10:50:38 controlplane systemd[1]: Started kubelet: The Kubernetes Node Agent.
Gdzie kubelet trzyma konfigurację ?
Spójrzmy na definicje pliku /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
[Service] Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" # This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env # This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use # the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file. EnvironmentFile=-/etc/default/kubelet ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
To co nas interesuje, to plik konfiguracyjny /var/lib/kubelet/config.yaml
Zobaczmy jego zawartość
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0sJak widać konfiguracja jest w postaci pliku YAML
W kontekście obiektów static pod należy zwrócić uwagę na zmienną staticPodPath
staticPodPath: /etc/kubernetes/manifests
Oczywiście możemy zapamiętać ten adres, z tym, że można czasem trafić na zadanie, gdzie albo nie ma jej skonfigurowanej, albo wskazuje na inny i nieoczywisty katalog.
Jak w tym schemacie mamy rozumieć, czym właściwie są obiekty static pod.
Konserwacja
Wyobraźmy sobie sytuację, gdy jeden z węzłów ulega awarii lub chcemy go poddać konserwacji (instalacja nowych wersji pakietów, niwelacja luk bezpieczeństwa. itp…).
Symulację takiej awarii można przeprowadzić za pomocą polecenia kubectl drain node-name.
Obiekty pod, które zostały poukładane na węźle przez scheduler zostaną z takiego węzła eksmitowane (evicted) , ale nie dotyczy to static pods i nie dotyczy obiektów kontrolowanych przez DaemonSet. Jeśli na danym węźle mamy obiekty pod w takiej konfiguracji to jawnie musimy podać, że należy je zignorować
kubectl drain node-name --ignore-daemonsets
O tym postaram się dokładniej napisać podczas ćwiczeń dotyczących instalacji i upgrade klastra za pomocą narzędzie kubeadm.
Zobaczmy jak wygląda plik manifestu kube-scheduler.yaml
cat /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: k8s.gcr.io/kube-scheduler:v1.18.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler
resources:
requests:
cpu: 100m
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kubeconfig
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kubeconfig
status: {}
To na co należy zwrócić uwagę to nazwa obiektu w obszarze metadata. name: kube-scheduler, obiekt jest wdrożony w przestrzeni nazw kube-system i nie ma wypełnionego znacznika nodeName. Jest wykorzystana sieć hosta hostNetwork: true.
To co widzimy z poziomu API-Server w przestrzeni nazw kube-scheduler
kubectl get pod -n kube-system
Przykładowa lista obiektów:
NAME READY STATUS RESTARTS AGE coredns-66bff467f8-bmwfk 1/1 Running 0 15m coredns-66bff467f8-vq78s 1/1 Running 0 15m etcd-controlplane 1/1 Running 0 14m kube-apiserver-controlplane 1/1 Running 0 14m kube-controller-manager-controlplane 1/1 Running 0 14m kube-flannel-ds-amd64-55njh 1/1 Running 0 15m kube-flannel-ds-amd64-t5shx 1/1 Running 0 15m kube-keepalived-vip-fplqp 1/1 Running 0 14m kube-proxy-886tw 1/1 Running 0 15m kube-proxy-pjxzf 1/1 Running 0 15m kube-scheduler-controlplane 1/1 Running 0 15m metrics-server-85f8dd85fd-msnhf 1/1 Running 0 15m
Pod kube-scheduler ma zmienioną nazwę i jest tak zwany mirror pod o nazwie kube-scheduler_node_name
Jak wygląda jego manifest, po usunięciu części danych które są wstrzyknięte przez klaster ?
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/config.hash: 74e2b561ea40b4f834f9854608d559d4
kubernetes.io/config.mirror: 74e2b561ea40b4f834f9854608d559d4
kubernetes.io/config.seen: "2021-06-04T11:01:30.654339598Z"
kubernetes.io/config.source: file
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler-controlplane
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: k8s.gcr.io/kube-scheduler:v1.18.0
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler
resources:
requests:
cpu: 100m
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kubeconfig
readOnly: true
hostNetwork: true
nodeName: controlplane
priority: 2000000000
priorityClassName: system-cluster-critical
tolerations:
- effect: NoExecute
operator: Exists
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kubeconfigI tutaj widzimy dodane nodeName: controlplane i zmieniona nazwę name: kube-scheduler-controlplane. To co należy zapamiętać, to brak możliwości tworzenia, usuwania i modyfikacji takich obiektów z poziomu kubectl, czyli przez API-Server. Takie obiekty są zmieniane jedynie przez wrzucenie nowego pliku, jego modyfikację lub usunięcie z katalogu, w którym kubelet danego węzła kontroluje zawartość zgodnie ze ścieżką staticPodPath.
Jak w praktyce odróżnić static pod bez logowania się na każdy węzeł i oglądania konfiguracji kubelet?
Zacznijmy od listy węzłów
kubectl get nodes
NAME STATUS ROLES AGE VERSION controlplane Ready master 21m v1.19.0 node01 Ready <none> 20m v1.19.0
Potem obejrzyjmy listę obiektów pod w przestrzeni nazw kube-system
kubectl get pod -n kube-system
Lista obiektów pod w przestrzeni nazw kube-system
NAME READY STATUS RESTARTS AGE coredns-66bff467f8-bmwfk 1/1 Running 0 39m coredns-66bff467f8-vq78s 1/1 Running 0 39m etcd-controlplane 1/1 Running 0 38m kube-apiserver-controlplane 1/1 Running 0 38m kube-controller-manager-controlplane 1/1 Running 0 38m kube-flannel-ds-amd64-55njh 1/1 Running 0 39m kube-flannel-ds-amd64-t5shx 1/1 Running 0 39m kube-keepalived-vip-fplqp 1/1 Running 0 38m kube-proxy-886tw 1/1 Running 0 39m kube-proxy-pjxzf 1/1 Running 0 39m kube-scheduler-controlplane 1/1 Running 0 29m metrics-server-85f8dd85fd-msnhf 1/1 Running 0 39m
Najłatwiej jest zauważyć, że sufiksem nazwy obiektu jest nazwa węzła (w naszym przypadku jest to controlplane).
Ale jeśli mamy klaster, który ma wiele węzłów, ten sposób może się okazać mało efektywny.
Innym sposobem jest weryfikacja obiektu kontrolującego dany obiekt pod i można wykorzystać pole, które wskazuje jaki obiekt nadrzędny jest tym który kontroluje jego stan.
kubectl describe pod -n kube-system | grep "Controlled By:"
Przykładowy rezultat
Controlled By: ReplicaSet/coredns-66bff467f8 Controlled By: ReplicaSet/coredns-66bff467f8 Controlled By: Node/controlplane Controlled By: ReplicaSet/katacoda-cloud-provider-6bc7d5d9ff Controlled By: Node/controlplane Controlled By: Node/controlplane Controlled By: DaemonSet/kube-flannel-ds-amd64 Controlled By: DaemonSet/kube-flannel-ds-amd64 Controlled By: DaemonSet/kube-keepalived-vip Controlled By: DaemonSet/kube-proxy Controlled By: DaemonSet/kube-proxy Controlled By: Node/controlplane Controlled By: ReplicaSet/metrics-server-85f8dd85fd
Łatwo zauważyć, że mamy obiekty kontrolowane przez DaemonSet,ReplicaSet (i w konsekwencji przez obiekt Deployment), ale pojawiają się też obiekty kontrolowane przez Node/nazwa-węzła)
Dane takie można też wyświetlić w bardziej eleganckiej formie wykorzystując, kubectl get (…) -o custom-columns.
Wykorzystaniu dokładniej custom-columns i jsonpath będzie dedykowany inny odcinek, tu mamy tylko mały przedsmak wykorzystania
https://stackoverflow.com/questions/43225591/kubernetes-custom-columns-select-element-from-array
https://kubernetes.io/docs/reference/kubectl/jsonpath/
kubectl get pods -n kube-system -o custom-columns=NAME:.metadata.name,CONTROLLER:.metadata.ownerReferences[].kind,NAMESPACE:.metadata.namespace
NAME CONTROLLER NAMESPACE coredns-66bff467f8-bmwfk ReplicaSet kube-system coredns-66bff467f8-vq78s ReplicaSet kube-system etcd-controlplane Node kube-system katacoda-cloud-provider-6bc7d5d9ff-t4zr2 ReplicaSet kube-system kube-apiserver-controlplane Node kube-system kube-controller-manager-controlplane Node kube-system kube-flannel-ds-amd64-55njh DaemonSet kube-system kube-flannel-ds-amd64-t5shx DaemonSet kube-system kube-keepalived-vip-fplqp DaemonSet kube-system kube-proxy-886tw DaemonSet kube-system kube-proxy-pjxzf DaemonSet kube-system kube-scheduler-controlplane Node kube-system metrics-server-85f8dd85fd-msnhf ReplicaSet kube-system
I dodatkowo można odfiltrować zwracany wynik, tylko dla obiektów static pod.
kubectl get pods --all-namespaces -o custom-columns=NAME:.metadata.name,CONTROLLER:.metadata.ownerReferences[].kind,NAMESPACE:.metadata.namespace |grep Node
etcd-controlplane Node kube-system kube-apiserver-controlplane Node kube-system kube-controller-manager-controlplane Node kube-system kube-scheduler-controlplane Node kube-system
Dosyć teorii, zabierzmy się za część praktyczną
Ćwiczenia
Zadanie pierwsze
Utwórz obiekt typu pod o nazwie static-nginx-node01 zawierający obraz nginx pracujący na porcie 80. Umieść go w przestrzeni nazw gamma i na węźle o nazwie node01. Obiekt powinien być kontrolowany przez API-Server. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć.
kubectl run static-nginx-node01 --image=nginx --port=80 -o yaml --dry-run=client > 01.pod.static-nginx-node01.yaml
Zawartość naszego manifestu
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: static-nginx-node01
name: static-nginx-node01
spec:
containers:
- image: nginx
name: static-nginx-node01
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
W jaki sposób umieścić pod na węźle node01 ?
Zacznijmy od najprostszego rozwiążania, nie może być to static pod, gdyż ma być kontrolowany przez API-Server, ale możemy wyręczyć kube-scheduler przez podanie jawnie nazwy węzła nodeName: node01.
Po dodaniu odpowiedniej przestrzeni nazw (tutaj gamma) nasz manifest powinien wyglądać tak:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: static-nginx-node01
name: static-nginx-node01
namespace: gamma
spec:
containers:
- image: nginx
name: static-nginx-node01
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
nodeName: node01
status: {}Wdrażamy nasz obiekt na klaster
kubectl apply -f 01.pod.static-nginx-node01.yaml
pod/static-nginx-node01 created
Zobaczmy, czy został umieszczony na odpowiednim węźle, w tym celu możemy wykorzystać jako parametr polecenia kubectl get pod -o wide
kubectl get pod static-nginx-node01 -n gamma -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES static-nginx-node01 1/1 Running 0 3m4s 10.244.2.13 node01 <none> <none>
Wszystko wygląda poprawie, ale czy jest to jedyne rozwiązanie ?
Co jeśli nie wypełnimy nodeName ? Czy obiekt zostanie wdrożony na inny węzeł niż node01 ? W naszym przypadku mamy do czynienia z małym dwuwęzłowym klastrem.
Bez podania nazwy wezła do akcji wkroczy kube-scheduler.
Uważna osoba zapyta się dlaczego kazałem nazwać obiekt z prefiksem static, a w zasadzie to nie jest to static pod. No wlaśnie dlatego, aby było to mniej oczywiste i podniosło poziom ćwiczenia.
Zadanie drugie
Utwórz obiekt typu pod o nazwie static-nginx-controlplane zawierający obraz nginx pracujący na porcie 80 . Umieść go w przestrzeni nazw gamma i na węźle o nazwie controlplane. Obiekt powinien być kontrolowany przez API-Server. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć. Kube-scheduler nie powinien brać udziału w ustaleniu docelowego węzła.
To zadanie jest praktycznie tym samym co zadanie pierwsze, ale warto przetestować jak działa nodeName dla węzła controlplane
kubectl run static-nginx-controlplane --image=nginx --port=80 -o yaml --dry-run=client > 02.pod.static-nginx-controlplane.yaml
Po dodaniu odpowiedniej przestrzeni nazw nasz manifest powinien wyglądać tak
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: static-nginx-controlplane
name: static-nginx-controlplane
namespace: gamma
spec:
containers:
- image: nginx
name: static-nginx-controlplane
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
nodeName: controlplane
status: {}Wdrażamy nasz obiekt na klaster
kubectl apply -f 02.pod.static-nginx-controlplane.yaml
pod/static-nginx-controlplane created
Zobaczmy, czy został umieszczony na odpowiednim węźle, w tym celu możemy wykorzystać jako parametr polecenia kubectl -o wide
kubectl get pod static-nginx-controlplane -n gamma -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES static-nginx-controlplane 1/1 Running 0 3m4s 10.244.2.13 controlplane <none> <none>
Jak widać z powyższych przykładów nodeName jest opcją atomową, z tym że ma jedną wadę. Musimy znać nazwy węzłów, a z tym bywa różnie w zależności od konfiguracji klastra.
Zadanie trzecie
Utwórz obiekt typu pod o nazwie static-nginx zawierający obraz nginx pracujący na porcie 80 . Umieść go w przestrzeni nazw gamma i na węźle o nazwie controlplane. Obiekt powinien być kontrolowany przez API-Server. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć. Kube-scheduler powinien brać udział w ustaleniu docelowego węzła. Należy wykorzystać mechanizm taints and tolerations.
Zacznijmy od mechanizmu taints and tolerations
kubectl describe nodes | egrep "Name:|Taints:"
Name: controlplane Taints: node-role.kubernetes.io/master:NoSchedule Name: node01 Taints: <none>
Standardowo, węzły kontrolujące klaster maja ustawiony zapach (taint), który uniemożliwia utworzenia na nich obiektów typu pod. Istnieje taka możliwość, ale wtedy należy w definicji obiektu uwzględnić tolerancję (toleration) na zapach danego węzła.
W jaki sposób można dodać zapach dla danego węzła ?
kubectl taint nodes controlplane key1=value1:NoSchedule
W jaki sposób dodać tolerację do obiektu pod?
na poziomie spec.tolerations
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
Gotowy manifest z dokumentacji Kubernetes wygląda tak
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/
kubectl run nginx-pod-master-tolerations -n gamma --image=nginx:1.18.0 --port=80 -o yaml --dry-run=client > 03.pod.nginx-pod-master-tolerations.yaml
Dodajemy do pliku z manifestem tolerację
tolerations: - key: "node-role.kubernetes.io/master" effect: "NoSchedule" nodeSelector: whereareyou: master
Oprócz dodania tolerancji niespodziewanie pojawił się nodeSelector. Dlaczego tak ? To, że dany obiekt jest odporny na zapach węzła controlplane nie oznacza, że musi być wdrożony na tym węźle.
Opcja nodeSelector pozwala nam wyjść z ograniczeniem nodeName jakim jest nazwa hosta i pozwala na filtrowanie tych węzłów, które maja odpowiednie etykiety
Przykładowy manifest z dokumentacji Kubernetes
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
W naszym przykładzie filtrujemy możliwośc wdrożenia obiektu pod tylko do węzłów, które mają ustawioną etykietę o nazwie disktype i wartości ssd

https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/
Wracamy do naszego zadania. Manifest powinien wyglądać tak
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod-master-tolerations
name: nginx-pod-master-tolerations
namespace: gamma
spec:
containers:
- image: nginx:1.18.0
name: nginx-pod-master-tolerations
ports:
- containerPort: 80
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
nodeSelector:
whereareyou: masterWdrażamy nasz obiekt na klaster
kubectl apply -f 03.pod.nginx-pod-master-tolerations.yaml
pod/static-nginx-controlplane created
Zobaczmy, czy został umieszczony na odpowiednim węźle, w tym celu możemy wykorzystać jako parametr polecenia kubectl -o wide
kubectl get pod static-nginx-controlplane -n gamma -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES static-nginx-controlplane 1/1 Running 0 3m4s 10.244.2.13 controlplane <none> <none>
A gdybyśmy jednak skorzystali z tolerancji i nie uzyłi nodeSelector ?
kubectl get nodes --show-labels
Mamy dwa węzły: controlplane i node01, a interesuje nas sposób wyboru węzła bez podawania wprost jego nazwy.
NAME STATUS ROLES AGE VERSION LABELS controlplane Ready master 32m v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=controlplane,kubernetes.io/os=linux,node-role.kubernetes.io/master=,whereareyou=master node01 Ready <none> 32m v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux,whereareyou=worker
Znajdzmy etykiety, którymi się różną oba węzły. To co nas interesuje to etykiety whereareyou=master dla węzła controlplane i whereareyou=worker dla węzła node01
kubectl label node controlplane whereareyou=master --overwrite kubectl label node node01 whereareyou=worker --overwrite
Opcja –overwrite nie zglosi blędu w przypadku, gdy dana etykieta jest juz nadana.
Bez ustawionego nodeSelector nasz manifest wyglądałby tak
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod-master-test
name: nginx-pod-master-test
namespace: gamma
spec:
containers:
- image: nginx:1.18.0
name: nginx-pod-master-test
ports:
- containerPort: 80
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
Sprobujmy wdrożyć nasz manifest nieco inaczej, korzystająć z kubectl -f –
cat <<EOF | kubectl apply -f - # Zawartość manifestu YAML EOF
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod-master-test
name: nginx-pod-master-test
namespace: gamma
spec:
containers:
- image: nginx:1.18.0
name: nginx-pod-master-test
ports:
- containerPort: 80
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
EOF
Zobaczmy, którym węźle wyląduje nasz obiekt
kubectl describe pod nginx-pod-master-test -n gamma
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 50s Successfully assigned gamma/nginx-pod-master-test to node01 Normal Pulling 48s kubelet, node01 Pulling image "nginx:1.18.0" Normal Pulled 42s kubelet, node01 Successfully pulled image "nginx:1.18.0" in 5.867211246s Normal Created 42s kubelet, node01 Created container nginx-pod-master-test Normal Started 41s kubelet, node01 Started container nginx-pod-master-test
Jak widać dodanie samej tolerancji nie gwarantuje, że obiekt znajdzie się na węźle, na którego zapach jest odporny, w naszym przypadku obiekt pod został umieszczony na węźle node01.
Zadanie czwarte
Utwórz obiekt typu pod o nazwie static-nginx zawierający obraz nginx pracujący na porcie 80 . Umieść go w przestrzeni nazw gamma i na węźle o nazwie controlplane. Obiekt nie powinien być kontrolowany przez API-Server. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć.
Ponieważ obiekt ma nie byc kontrolowany przez API-Server bedziemy musili zbudować static pod
kubectl run static-nginx --image=nginx --port=80 -o yaml --dry-run=client > 04.pod.static-nginx.yaml
Dodajemy brakującą przestzreń nazw gamma
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: static-nginx
name: static-nginx
namespace: gamma
spec:
containers:
- image: nginx
name: static-nginx
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Wdrożenie polega na przekopiowaniu pliku do odpowiedniej ścieżki kontrolowanej przez kubelet
cp 04.pod.static-nginx.yaml /etc/kubernetes/manifests/
Po chwili widzimy już nasz mirror pod
kubectl get pod static-nginx-controlplane -n gamma -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES static-nginx-controlplane 1/1 Running 0 2m41s 10.244.0.4 controlplane <none> <none>
Zadanie piąte
Utwórz obiekt typu pod o nazwie static-nginx zawierający obraz nginx:1.18.0 pracujący na porcie 80. Umieść go w przestrzeni nazw gamma i na węźle o nazwie node01. Obiekt nie powinien być kontrolowany przez API-Server. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć.
Ponieważ obiekt ma nie być kontrolowany przez API-Server bedziemy musieli zbudować static pod, tym razem na węzle node01. Jest tu pewna pułapka. Zmianę węzłów na klastrze podczas egzaminu dokonujemy przez ssh student@nazwa_wezla a potem pracujemy na prawach uzytkownika root za pomocą sudo -i
Po zalogowaniu się na węzeł node01 okaże się, ze nie ma tam pliku binarnego kubectl. Co można zrobić ?
Wykonać poniższy kod na węźle controlplane (tu jest kubectl) i wkleić manifest do schowka (ten schowek po to jest między innymi). Następnie uruchamiamy edytor vim i wklejamy zawartość.
kubectl run static-nginx --image=nginx --port=80 -o yaml --dry-run=client > 05.pod.static-nginx.yaml
Pozostaje nam tylko poprawa manifestu i wrzucenie pliku do odpowiedniego katalogu na wężle.
Zadanie szóste
kubectl run nginx-pod-worker-selector -n gamma --image=nginx:1.18.0 --port=80 -o yaml --dry-run=client >06.pod.nginx-pod-worker-selector.yaml
Przypomnijmy sobie jeszcze raz etykiery węzłów naszego klastra
kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS controlplane Ready master 32m v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=controlplane,kubernetes.io/os=linux,node-role.kubernetes.io/master=,whereareyou=master node01 Ready <none> 32m v1.19.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux,whereareyou=worker
Jak widać węzeł node01 ma ustawioną etykietę whereareyou o wartości worker.
Podczas edycji pliku należy dodać
nodeSelector: whereareyou: worker
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod-worker-selector
name: nginx-pod-worker-selector
namespace: gamma
spec:
containers:
- image: nginx:1.18.0
name: nginx-pod-worker-selector
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
nodeSelector:
whereareyou: worker
status: {}
kubectl apply -f 06.pod.nginx-pod-worker-selector.yaml
Łatwo zweryfikować, czy wdrożenie zostało poprawnie przeprowadzone
kubectl describe pod nginx-pod-worker-selector -n gamma
Odfiltrowana część zwrotna, pokazuje, że wykorzystano nodeSelector i jaki oraz, który węzeł został wybrany jako właściwy
... Node-Selectors: whereareyou=worker ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 10s Successfully assigned gamma/nginx-pod-worker-selector to node01 ...
Zadanie siódme
kubectl run nginx-pod-master-tolerations -n gamma--image=nginx:1.18.0 --port=80 -o yaml --dry-run=client > 07.pod.nginx-pod-master-tolerations.yaml
Do tak wygenerowanego manifestu należy dodać tolerancję, na zapach węzła controlplane, ale dodatkowo również wybór węzła za pomocą etykiety. Węzeł controlplane ma ustawioną etykietę whereareyou o wartości master.
tolerations: - key: "node-role.kubernetes.io/master" effect: "NoSchedule" nodeSelector: whereareyou: master
kubectl apply -f 07.pod.nginx-pod-master-tolerations.yaml
możemy zweryfikować, stan naszego zasobu.
kubectl describe pod nginx-pod-master-tolerations -n gamma | grep "Tolerations" kubectl describe pod nginx-pod-master-tolerations -n gamma | grep "Node-Selectors"
Tolerations: node-role.kubernetes.io/master:NoSchedule Node-Selectors: whereareyou=master Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 3m1s Successfully assigned gamma/nginx-pod-master-tolerations to controlplane Normal Pulled 3m1s kubelet, controlplane Container image "nginx:1.18.0" already present on machine Normal Created 3m kubelet, controlplane Created container nginx-pod-master-tolerations Normal Started 3m kubelet, controlplane Started container nginx-pod-master-tolerations
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod-master-tolerations
name: nginx-pod-master-tolerations
namespace: gamma
spec:
containers:
- image: nginx:1.18.0
name: nginx-pod-master-tolerations
ports:
- containerPort: 80
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
nodeSelector:
whereareyou: master
status: {}Wdrażamy nasz obiekt z pliku i przechodzimy do kolejnego wyzwania
Zadanie ósme
kubectl get pod -n kube-system -l component=kube-scheduler
Tutaj wykorzystalem etykietę o nazwie component i wartości kube-scheduler.
NAME READY STATUS RESTARTS AGE kube-scheduler-controlplane 1/1 Running 0 33m
Mamy do czynienia z obiektem typu static pod (suffiks z nazwą węzła)
cp /etc/kubernetes/manifests/kube-scheduler.yaml /tmp/my-scheduler.yaml
W nowym pliku należy dokonać kilku modyfikacji. Po piewsze nie mogą istnieć dwa obiekty o tej samej nazwie w tej samej przestrzeni nazw. Po drugie hostNetwork: true oznacza,że obiekt korzysta bezpośrednio z sieci danego węzła, co w praktyce oznacza, ze nie można uruchomić w takim samym trybie kolejnego obiektu z obsługującego ten sam port i protokół.
Zmieniamy nazwę obiektu na my-scheduler i dodajemy
- --leader-elect=false - --port=54321 - --secure-port=54322 - --scheduler-name=my-scheduler
Wybór lidera (leader election) to mechanizm, który gwarantuje, że tylko jedna instancja schedulera aktywnie podejmuje decyzje, podczas gdy pozostałe instancje sa nieaktywne, ale są przygotowane by to zrobić, gdy lider przestanie funkcjonować.
Jednocześnie należy pamiętać o zmianie numerów portów dla sond gotowości (readiness) i żywotności (liveness), czy startu (startup)
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=false
- --port=54321
- --secure-port=54322
- --scheduler-name=my-scheduler
image: k8s.gcr.io/kube-scheduler:v1.19.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 54322
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-scheduler
resources:
requests:
cpu: 100m
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /healthz
port: 54322
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kubeconfig
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kubeconfig
status: {}
cp /tmp/my-scheduler.yaml /etc/kubernetes/manifests/
kubectl get pod -n kube-system -l component=kube-scheduler
Mamy dwa działające obiekty:
NAME READY STATUS RESTARTS AGE kube-scheduler-controlplane 1/1 Running 0 26m my-scheduler-controlplane 1/1 Running 0 100s
kubectl logs my-scheduler-controlplane -n kube-system
Przykładowe logi
I0611 19:16:55.006677 1 registry.go:173] Registering SelectorSpread plugin I0611 19:16:55.006762 1 registry.go:173] Registering SelectorSpread plugin I0611 19:16:55.509219 1 serving.go:331] Generated self-signed cert in-memory I0611 19:16:56.190034 1 registry.go:173] Registering SelectorSpread plugin I0611 19:16:56.190064 1 registry.go:173] Registering SelectorSpread plugin W0611 19:16:56.192607 1 authorization.go:47] Authorization is disabled W0611 19:16:56.192625 1 authentication.go:40] Authentication is disabled I0611 19:16:56.192633 1 deprecated_insecure_serving.go:51] Serving healthz insecurely on [::]:54321 I0611 19:16:56.196239 1 requestheader_controller.go:169] Starting RequestHeaderAuthRequestController I0611 19:16:56.196258 1 shared_informer.go:240] Waiting for caches to sync for RequestHeaderAuthRequestController I0611 19:16:56.196282 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::client-ca-file I0611 19:16:56.196295 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::client-ca-file I0611 19:16:56.196318 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I0611 19:16:56.196322 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I0611 19:16:56.197259 1 secure_serving.go:197] Serving securely on 127.0.0.1:54322 I0611 19:16:56.197739 1 tlsconfig.go:240] Starting DynamicServingCertificateController I0611 19:16:56.296585 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file I0611 19:16:56.296979 1 shared_informer.go:247] Caches are synced for RequestHeaderAuthRequestController I0611 19:16:56.296995 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::client-ca-file
Zadanie dziewiąte
Utwórz obiekt typu deployment o nazwie nazwie nginx-deployment-my-scheduler zawierający obraz nginx:1.18.0 pracujący na porcie 80. Umieść go w przestrzeni nazw gamma. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć. Obiekt powinien wykorzystać wdrożony w poprzednim zadaniu scheduler o nazwie my-scheduler
kubectl create deployment nginx-deployment-my-scheduler --image=nginx:1.18.0 --namespace=gamma--port=80 -o yaml --dry-run=client > 09.deploy.deploy-nginx-my-scheduler.yaml
vim 09.deploy.deploy-nginx-my-scheduler.yaml
Należy dodać na poziomie spec nazwę schedulera
spec: schedulerName: my-scheduler
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-my-scheduler
name: nginx-deployment-my-scheduler
namespace: gamma
spec:
replicas: 1
selector:
matchLabels:
app: nginx-deployment-my-scheduler
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-my-scheduler
spec:
containers:
- image: nginx:1.18.0
name: nginx
ports:
- containerPort: 80
resources: {}
schedulerName: my-scheduler
Wdrażamy nasz manifest na klaster
kubectl apply -f 09.deploy.deploy-nginx-my-scheduler.yaml
deployment.apps/nginx-deployment-my-scheduler created
Zobaczmy jak wygląda nasze wdrożenie
kubectl get all -n gamma -l app=nginx-deployment-my-scheduler
NAME READY STATUS RESTARTS AGE pod/nginx-deployment-my-scheduler-7d5d5f5dcf-brrp9 1/1 Running 0 110s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx-deployment-my-scheduler 1/1 1 1 110s NAME DESIRED CURRENT READY AGE replicaset.apps/nginx-deployment-my-scheduler-7d5d5f5dcf 1 1 1 110s
Warto przeczytać część oficjalnej dokumentacji jak sobie radziś z konfiguracją wielu schedulerów na klastrze, tu jedynie po raz kolejny podrapałem powierzchnię.
https://kubernetes.io/docs/tasks/extend-kubernetes/configure-multiple-schedulers/
Zadanie dziesiąte
Utwórz obiekt typu service o nazwie nginx-service-deployment-myscheduler który wystawi obiekt deployment o nazwie nginx-deployment-my-scheduler za pomocą typu ClusterIP i na porcie 80. Obiekt należy umieścić w przestrzeni nazw gamma. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć.
kubectl expose deploy/nginx-deployment-my-scheduler -n gamma --name nginx-service-deployment-my-scheduler -o yaml --dry-run=client > 10.service.nginx-service-deploymeny-nginx-my-scheduler.yaml
vim 10.service.nginx-service-deploymeny-nginx-my-scheduler.yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-my-scheduler
name: nginx-service-deployment-my-scheduler
namespace: gamma
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-deployment-my-scheduler
status:
loadBalancer: {}
Po wdrożeniu manifestu na klaster
kubectl apply -f 10.servicenginx-service-deployment-my-scheduler.yaml
przechodzimy do następnego wyzwania.
Zadanie jedenaste
Utwórz obiekt typu deployment o nazwie nazwie nginx-deployment-all-nodes zawierający obraz nginx:1.18.0 pracujący na porcie 80. Umieść go w przestrzeni nazw gamma. Jeżeli przestrzeń nazw nie istnieje należy ją utworzyć. Ustaw liczbę replik na pięć (5), ważne by przekroczyć liczbę węzłów worker naszego klastra. Obiekt powinien wykorzystać wdrożony w poprzednim zadaniu scheduler o nazwie my-scheduler. Wykorzystaj mechanizm podAntiAffinity. Jak etykietę ustaw app: nginx-deployment-all-nodes.
Zacznijmy od wyjaśnienia czym jest ten mechanizm.
Wyobrażmy sobie, że nasza aplikacja składa się z dwóch obiektów pod: podA i podB, a chcemy ją wdrożyć w taki sposób, aby podA został równomiernie rozmieszczony na każdym węźle roboczym. Natomiast podB znalazł się maksymalnie blisko obiektu podA.
Etykiety dla podA to app: podA, dla podB app: podB
Dwa mechanizmy, które tu można zastosowac to
- podAffinity dla obiektu podB
Przykładowy fragment manifestu dla spec.
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- podA
topologyKey: "kubernetes.io/hostname"
- podAntiAffinity dla obiektu podA
Przykładowy fragment manifestu
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- podA
topologyKey: "kubernetes.io/hostname"
lub w nieco innej wersji
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- podA
topologyKey: "kubernetes.io/hostname"
Obostrzenie może być wprowadzone w dwóch trybach
twardym (hard) requiredDuringSchedulingIgnoredDuringExecution, blokujemy rozkład na węzły jeśli warunek będzie spełniony
miękkim (soft) preferredDuringSchedulingIgnoredDuringExecution, sugerujemy rozkład na węzły jeśli warunek będzie spełniony
The operator może przejąć następujące wartości In, NotIn, Exists, or DoesNotExist. Dla przykładu można uzyć In aby zweryfikować czy etykieta związana z obiektem pod jest wdrożona na węźle ( stąd topologyKey wskazujący nazwę węzła)
W przypadku antiAffinity należy jeszcze dodać weight z wartością od 1 do 100, im większą wartość, wym większa waga.
Nie uczmy się tego na pamięć, ważne by wiedzieć gdzie znaleźć w dokumentacji przykładowe manifesty i jak je modyfikować w zależności od wymagań danego zadania.
Można też wykorzystać jednoczeście oba mechanizmy na raz.
Przykład nas postawie dokumentacji https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: "kubernetes.io/hostname"
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: "kubernetes.io/hostname"
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
https://github.com/infracloudio/kubernetes-scheduling-examples/blob/master/podAffinity/README.md
Dla trybu soft należy dodać wagę (weight) jego reguły. Można tych reguł zbudować więcej niż jedną, gdyż możemy mieć na przykład do czynienia z kilkoma rodzajami obiektów pod
(podA, podB, podC, ….) i wtedy mamy sposób na określenie, które z tych reguł maja większe znaczenie.
Wracając do części praktycznej, przygotowaliśmy nasz manifest, dodaliśmy mechanizm antiAffinity i wskazaliśmy, który scheduler ma przygotować proces wyznaczenia docelowego węzła. Nasz plik wygląda tak
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-all-nodes
name: nginx-deployment-all-nodes
namespace: gamma
spec:
replicas: 5
selector:
matchLabels:
app: nginx-deployment-all-nodes
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-all-nodes
spec:
containers:
- image: nginx:1.18.0
name: nginx
ports:
- containerPort: 80
resources: {}
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-deployment-all-nodes
topologyKey: "kubernetes.io/hostname"
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
schedulerName: my-scheduler
Wdrażamy na nasz dwuwęzłowy klaster (controlplane + node01)
kubectl get all -n gamma -l app=nginx-deployment-all-nodes
NAME READY STATUS RESTARTS AGE pod/nginx-deployment-all-nodes-594c6c5777-b257x 0/1 Pending 0 37s pod/nginx-deployment-all-nodes-594c6c5777-g7dqc 0/1 Pending 0 37s pod/nginx-deployment-all-nodes-594c6c5777-mlgmc 0/1 Pending 0 37s pod/nginx-deployment-all-nodes-594c6c5777-vtc8k 1/1 Running 0 37s pod/nginx-deployment-all-nodes-594c6c5777-x8t8w 1/1 Running 0 37s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx-deployment-all-nodes 2/5 5 2 37s NAME DESIRED CURRENT READY AGE replicaset.apps/nginx-deployment-all-nodes-594c6c5777 5 5 2 37s
Zauważmy, że tylko dwa obiekty pod są w statusie running, pozostałe w statusie pending.
Sprawdzmy, na których węzłach pojawiły się te pierwsze
Ponieważ obiekt pod i deployment są otagowane w ten sam sposób, czyli app: nginx-deployment-all-nodes łatwo odfiltrować te obiekty, które nas interesują
kubectl get pod -n gamma -l app=nginx-deployment-all-nodes -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-all-nodes-594c6c5777-b257x 0/1 Pending 0 81s <none> <none> <none> <none> nginx-deployment-all-nodes-594c6c5777-g7dqc 0/1 Pending 0 81s <none> <none> <none> <none> nginx-deployment-all-nodes-594c6c5777-mlgmc 0/1 Pending 0 81s <none> <none> <none> <none> nginx-deployment-all-nodes-594c6c5777-vtc8k 1/1 Running 0 81s 192.168.49.65 controlplane <none> <none> nginx-deployment-all-nodes-594c6c5777-x8t8w 1/1 Running 0 81s 10.244.1.9 node01
Dlaczego tak się stało, pozostałe trzy instancje nie moga być wdrożone ani na węzeł controlplane ani na node01, gdyż na każdym z nich pojawił się już instancja z etykietą app o wartości nginx-deployment-all-nodes. Reguła requiredDuringSchedulingIgnoredDuringExecution działa w wersji twardej (hard) i blokuje wybór węzła
Dobrze jest to widoczne w zdarzeniach (events) danej przestrzeni nazw. Tu przy okazji warto zapamitętać, jak poprawnie sortować zdarzenia za pomocą –sort-by
kubectl get events -n gamma --sort-by=.metadata.creationTimestamp | grep anti
<unknown> Warning FailedScheduling pod/nginx-deployment-all-nodes-594c6c5777-b257x 0/2 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules. <unknown> Warning FailedScheduling pod/nginx-deployment-all-nodes-594c6c5777-g7dqc 0/2 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules. <unknown> Warning FailedScheduling pod/nginx-deployment-all-nodes-594c6c5777-mlgmc 0/2 nodes are available: 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules.
Jak można rozwiązać taki problem ?
Zmieniająć wersję twardą na miękką (soft), czyli zamiast requiredDuringSchedulingIgnoredDuringExecution użyć preferredDuringSchedulingIgnoredDuringExecution.
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-all-nodes
name: nginx-deployment-all-nodes
namespace: gamma
spec:
replicas: 5
selector:
matchLabels:
app: nginx-deployment-all-nodes
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx-deployment-all-nodes
spec:
containers:
- image: nginx:1.18.0
name: nginx
ports:
- containerPort: 80
resources: {}
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx-deployment-all-nodes
topologyKey: "kubernetes.io/hostname"
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
schedulerName: my-scheduler
kubectl get pod -n gamma -l app=nginx-deployment-all-nodes -o wide
Jak widać na poniższym, dwa obiekty są na jednym węźle a trzy na drugim.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-all-nodes-865f8cb865-5tnxj 1/1 Running 0 6s 10.244.1.15 node01 <none> <none> nginx-deployment-all-nodes-865f8cb865-7ftpz 1/1 Running 0 6s 192.168.49.67 controlplane <none> <none> nginx-deployment-all-nodes-865f8cb865-h5f78 1/1 Running 0 6s 10.244.1.16 node01 <none> <none> nginx-deployment-all-nodes-865f8cb865-nvjc7 1/1 Running 0 6s 10.244.1.17 node01 <none> <none> nginx-deployment-all-nodes-865f8cb865-zv5nd 1/1 Running 0 6s 192.168.49.66 controlplane <none> <none>
Na tym kończymy dzisiejszą audycję, do usłyszenia wkrótce.
Poprzednie części
Certified Kubernetes Administrator (CKA) krok po kroku – część 1
Certified Kubernetes Administrator (CKA) krok po kroku – część 2
Certified Kubernetes Administrator (CKA) krok po kroku – część 3
Następne części
TODO
Literatura:
https://blog.mayadata.io/openebs/static-pods-in-kubernetes
https://dev.to/chuck_ha/reading-kubernetes-logs-315k
https://stackoverflow.com/questions/43225591/kubernetes-custom-columns-select-element-from-array
https://kubernetes.io/docs/reference/kubectl/jsonpath/
https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/
https://www.tutorialworks.com/difference-docker-containerd-runc-crio-oci/
https://kubernetes.io/docs/tasks/extend-kubernetes/configure-multiple-schedulers/
Dodaj komentarz