
Jednym z początkowych problemów z jakimi natknąłem się podczas pracy z płytką Nvidia Jetson Nano był długi czas potrzebny do konfiguracji nowego środowiska wirtualnego w Pythonie. System operacyjny uruchamiany z karty microSD i potrzeba kompilacji poszczególnych bibliotek, które umożliwiały uruchamianie modeli uczenia maszynowego z wykorzystaniem GPU w nie należały w sumie do demonów prędkości. Trudno się dziwić, nieco inne jest zastosowanie tego typu urządzeń elektronicznych. Zacząłem się zastanawiać, czy zamiast budowy osobnych środowisk wirtualnych dla pakietu Keras z TensorFlow, dla pakietu Pytorch i pakietu Scikit-Learn, wykorzystać możliwość budowy gotowych obrazów w skonteneryzowanej postaci.
Niniejszy wpis jest próbą weryfikacji takiej konfiguracji.
Instalacja
Zdecydowałem się na zakup nowej karty microSD o wielkość 128GB.
Na początku ściągnąłem obraz
https://developer.nvidia.com/embedded/jetpack
Zainteresowało mnie jedno zdanie:
“In addition to the features listed below, JetPack 4.2.1 also introduced two beta features: NVIDIA Container Runtime with Docker integration and TensorRT support for INT-8 DLA operations.”
Obraz zajmuje ok 5GB. Po rozpakowaniu pliku nagrałem go na kartę za pomocą programu Balena Etcher.
Po zakończeniu wgrywania obrazu na kartę microSD nadszedł czas na uruchomienie oprogramowania.
Po pierwszym uruchomieniu systemu Ubuntu nadszedł czas na konfigurację
Przy okazji warto zaktualizować czas systemowy
sudo date --set "27 Oct 2019 15:08:00"

Jak widać silnik konteneryzacji (Docker) jest już zainstalowany, ale do sprawnego działanie będziemy musieli zaktualizować jego wersję (do wersji 19.03 w momencie pisania tego artykułu).
W razie problemów z DNS należy do pliku /etc/systemd/resolved.conf dodać główny DNS Google lub preferowany inny
DNS=8.8.8.8 2001:4860:4860::8888
FallbackDNS=8.8.4.4 2001:4860:4860::8844Założyłem, że wszelkie kompilacje oprogramowania wykonam na środowisku natywnym (Jetson Nano).
W tym momencie warto dodać plik wymiany, gdyż wolna pamięć 4GB może się okazać chwilami zasobem zanikającym.
#!/bin/bash
sudo fallocate -l 8G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
echo "/swapfile swap swap defaults 0 0" | sudo tee --append /etc/fstab > /dev/null
Dokonujemy aktualizacji silnika Docker
sudo apt-get install curl -y
curl -sSL https://get.docker.com/ | sh
Po zakończeniu instalacji mamy już wersję 19.03
Client: Docker Engine - Community Version: 19.03.4 API version: 1.40 Go version: go1.12.10 Git commit: 9013bf5 Built: Fri Oct 18 15:52:24 2019 OS/Arch: linux/arm64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.4 API version: 1.40 (minimum version 1.12) Go version: go1.12.10 Git commit: 9013bf5 Built: Fri Oct 18 15:50:53 2019 OS/Arch: linux/arm64 Experimental: false containerd: Version: 1.2.10 GitCommit: b34a5c8af56e510852c35414db4c1f4fa6172339 runc: Version: 1.0.0-rc8+dev GitCommit: 3e425f80a8c931f88e6d94a8c831b9d5aa481657 docker-init: Version: 0.18.0 GitCommit: fec3683
Budowa obrazów
Należy uzbroić się w cierpliwość, budowa jednego obrazu to co najmniej godzina czasu. Może się to wydawać długim czasem, ale jeden z wpisów na blogu, który przeczytałem o walkach autora z instalacją Tensorflow 2.0 doprowadził do jedynego słusznego wniosku, że taki sposób rozwoju oprogramowania to droga donikąd.
Note this script would take a very long time (~40 hours) to run.
To była dodatkowa motywacja, by przygotować raz, a dobrze podstawowe zbiory pakietów dla uczenia maszynowego, czy nawet uczenia głębokiego z wykorzystaniem GPU. Wyobraźmy sobie, że karta SD, na której uruchamiamy system operacyjny ulega uszkodzeniu, co wtedy, kolejne godziny kompilacji? Co jest ważniejsze, trenowanie i rozbudowa modelu, czy wieczna konfiguracja i instalacja? I o tym jest poniższa opowieść.
Dla osób, które chcą zamiast wykonywania poleceń z poziomu linii komend wykorzystać interfejs w przeglądarce polecam instalację Portainera.
Można pobrać gotowy obraz Portainera
# pobieramy z repozytorium
docker pull portainer/portainer
# uruchamiany w trybie automatycznego restartu
docker run -d -p 9000:9000 --name portainer --restart always -v /var/run/docker.sock:/var/run/docker.sock portainer/portainer
Aplikacja uruchomiona zostanie na porcie 9000 hosta, jeśli chcemy korzystać z naszego laptopa można forwardować port 9000 przy konfiguracji łącza SSH.
Po utworzeniu konta administratorskiego wraz z hasłem i zalogowaniu się należy podłączyć się do lokalnego silnika Dockera.
Od tego momentu wszystkie podane niżej operacje będzie można wykonać z poziomu przeglądarki. Przykładowy tutorial można znaleźć np. tutaj:
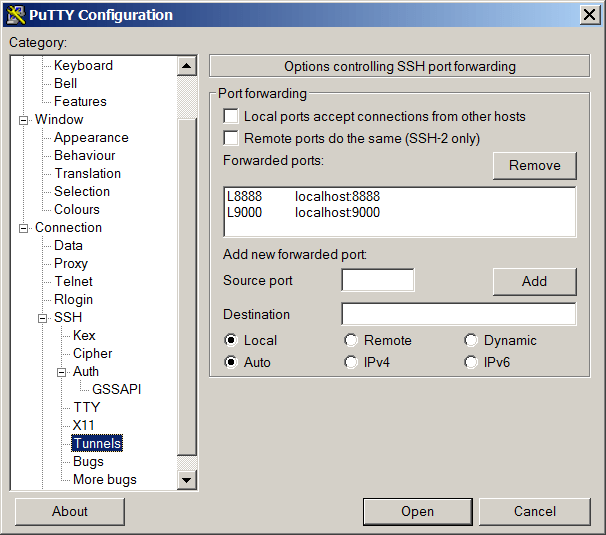
W tym momencie warto zrobić forwardowanie dla portu 8888, który będzie wykorzystywany przez Jupyter Lab/Notebook. W popularnym kliencie SSH Putty wygląda to tak:
Zaczynamy właściwą zabawę.
Pobieramy bazowy obraz z repozytorium NVidia
Jest to przygotowane oprogramowanie dobrze współpracujące z architekturą ARM 64-bit i procesorami GPU serii Tegra.
sudo docker pull nvcr.io/nvidia/l4t-base:r32.2.2
Prace na nowo uruchomionym systemie operacyjnym możemy rozpocząć od sklonowania repozytorium:
git clone https://github.com/djkormo/jetson-nano.git
Kod znajduje się w podkatalogu ml-containers
Postanowiłem przygotować trzy obrazy zawierające różne grupy oprogramowania do uczenia maszynowego:
1) Scikit-learn, ale tu nie będzie wsparcia GPU zgodnie z:
https://scikit-learn.org/stable/faq.html
2) Tensorflow plus Keras z obsługą GPU
3) Pytorch z obsługą GPU.
Dodatkowo rozszerzyłem te obrazy o najbardziej popularne pakiety (scipy,numpy, pandas, folium, matplotlib, seaborn), ten wybór jest autorski i wynika z doświadczeń typowego wykorzystywana dodatkowych pakietów do wstępnego przetwarzania danych wejściowych i ich wizualizacji.
Każdy z tych obrazów można będzie dodatkowo rozszerzyć o instalację Jupyter Notebook i Jupyter Lab.
Wszystkie obrazy zostaną umieszczone publicznym repozytorium Docker Hub.
Skrypty budujące i zawartość Dockerfile oraz przykładowe pliki Pythona czy notatniki Jupytera umieściłem w repozytorium Githuba. Kod będzie sukcesywnie rozwijany. Liczę na konstruktywne uwagi.
https://github.com/djkormo/jetson-nano/tree/master/ml-containers
Dla każdego z obrazów przygotowałem podkatalog zawierające przynajmniej następujące pliki
A. Dockerfile – plik zwierający instrukcję budowy naszego obrazu
FROM nvcr.io/nvidia/l4t-base:r32.2
WORKDIR /home
RUN apt-get update && apt-get install -y --fix-missing make g++ libblas-dev liblapack-dev libatlas-base-dev gfortran
RUN apt-get update && apt-get install -y --fix-missing python3-pip libhdf5-serial-dev hdf5-tools libfreetype6-dev
RUN apt-get update && apt-get install -y python3-h5py
RUN pip3 install --pre --no-cache-dir --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu
RUN pip3 install -U --pre --no-cache-dir numpy
RUN pip3 install --no-cache-dir folium seaborn keras
RUN update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 1
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3 1
COPY test.py test.py
CMD [ "bash" ]
Zwracam uwagę na kilka podstawowych zasad, które przyjąłem przy budowie aplikacji
- Korzystamy z tego samego obrazu bazowego nvcr.io/nvidia/l4t-base:r32.2
- Instalujemy potrzebne oprogramowanie (ten punkt był najbardziej pracochłonny, gdyż dopiero podczas etapu kompilacji pojawiały się błędy braku zależności)
- Dedykowane oprogramowanie (Tensorflow, Pytorch) pochodzi z repozytorium NVidia dla kart GPU Tegra
- Dedykowane polecenia python3 i pip3 zostaną zmapowane do python i pip. Wersja 2.7 Pythona nie będzie wykorzystywana
- Dodany zostanie przynajmniej jeden plik z testowym kodem (test.py)
B. build.bash – polecenia umożliwiający sprawną budowę obrazu i jego wypchnięcie do publicznego repozytorium
#!/bin/bash
DOCKER_REGISTRY=docker.io
DOCKER_PROJECT_ID=djkormo
SERVICE_NAME=jetson-pytorch-base:0.1.0
DOCKER_IMAGE_NAME=$DOCKER_PROJECT_ID/$SERVICE_NAME
DOCKER_IMAGE_REPO_NAME=$DOCKER_REGISTRY/$DOCKER_IMAGE_NAME
echo "DOCKER_REGISTRY: $DOCKER_REGISTRY"
echo "DOCKER_PROJECT_ID: $DOCKER_PROJECT_ID"
echo "SERVICE_NAME: $SERVICE_NAME"
echo "DOCKER_IMAGE_NAME: $DOCKER_IMAGE_NAME"
echo "DOCKER_IMAGE_REPO_NAME: $DOCKER_IMAGE_REPO_NAME"
# build
docker build -t $SERVICE_NAME . -f Dockerfile
# tag
docker tag $SERVICE_NAME $DOCKER_IMAGE_NAME
#push
docker push $DOCKER_IMAGE_NAME
C. run_local.bash – polecenie uruchamiające kontener na podstawie zbudowanego obrazu
W przypadku kontenerów bazowych (bez oprogramowania Jupyter) uruchamiam oprogramowanie w trybie interaktywnym
docker run -it --runtime=nvidia --network=host djkormo/jetson-tensorflow-base:0.1.0
W przypadku kontenerów dodatkowych uruchamiam oprogramowanie z podaniem mapowania portu kontenera na port host bez trybu interaktywnego
docker run -d --runtime=nvidia -p 8888:8888 djkormo/jetson-tensorflow-jlab:0.1.0
Należy pamiętać o opcji –runtime=nvidia, inaczej nie będzie możliwości wykorzystania procesora graficznego.
D. test.py – plik zawierający testowy kod weryfikujący poprawność instalacji (w szczególności wykorzystanie GPU hosta).
Ten kod należy wykonać wewnątrz kontenera.
Czasem wystarczy proste sprawdzenie, czy GPU Hosta jest widoczne w kontenerze, przykładowo dla biblioteki Pytorch:
import torch
print("torch.__version__",torch.__version__)
print("torch.cuda.current_device()",torch.cuda.current_device())
print("torch.cuda.device(0)",torch.cuda.device(0))
print("torch.cuda.device_count()",torch.cuda.device_count())
print("torch.cuda.get_device_name(0)",torch.cuda.get_device_name(0))
print("torch.cuda.is_available()",torch.cuda.is_available())
Po uruchomieniu kontenera wystarczy wpisać polecenie
python test.py.
Proces budowania składa się z następujących kroków
1. Przygotowanie pliku Dockerfile
2 Przygotowanie pliku budującego build bash
Uruchomienie polecenia bash build.bash
3. Przygotowanie pliku lokalnego uruchomienia run_local.bash
Uruchomienie polecenia bash run_local.bash
Punkty od 1) do 3) mają charakter cykliczny, do czasu uzyskania działającego oprogramowania przetestowanego odpowiednim skryptem (*.py).
Uwaga na pakiet Pytorch
W przypadku pakietu Pytorch pojawił się pewien problem, nie udało się skompilować pakietu torchvision w sposób automatyczny. Poradziłem sobie w następujący sposób.
1. Po zbudowaniu obrazu o nazwie jetson-pytorch-base:0.1.0 uruchomiłem go z opcją –runtime=nvidia
2. Wewnątrz kontenera doinstalowałem brakujący pakiet (jak zwykle należy się uzbroić w cierpliwość)
cd torchvision
python3 setup.py install
3. Po zbudowaniu pakietu skorzystałem z możliwości zatwierdzenia zmian z punktu 2)
Stworzyłem dedykowany kawałek kodu
#!/bin/bash
CONTAINER_ID=$(docker ps -qf "ancestor=djkormo/jetson-pytorch-base:0.1.0")
docker commit $CONTAINER_ID djkormo/jetson-pytorch-base:0.2.0
# push to repo
docker push djkormo/jetson-pytorch-base:0.2.0
Obrazy, które zostały umieszczone w repozytorium DockerHub.
bazowe
https://hub.docker.com/r/djkormo/jetson-scikit-base
https://hub.docker.com/r/djkormo/jetson-tensorflow-base
https://hub.docker.com/r/djkormo/jetson-pytorch-jlab
z dodatkiem Jupyter Lab
https://hub.docker.com/r/djkormo/jetson-scikit-jlab
https://hub.docker.com/r/djkormo/jetson-tensorflow-jlab
https://hub.docker.com/r/djkormo/jetson-pytorch-jlab
Demonstracja:
Korzystając z przygotowanego obrazu uruchamiamy kontener w trybie detach z wystawionym portem 8888 hosta.
docker run -d --runtime=nvidia -p 8888:8888 djkormo/jetson-tensorflow-jlab:0.1.0
Po uruchomieniu obrazu djkormo/jetson-pytorch-jlab:0.1.0 mamy możliwość rozpoczęcia testu na przygotowanym notatniku Jupyter. Zawiera on prosty model konwolucyjny wykorzystujący klasyczny zbiór danych Cifar10.
Net( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
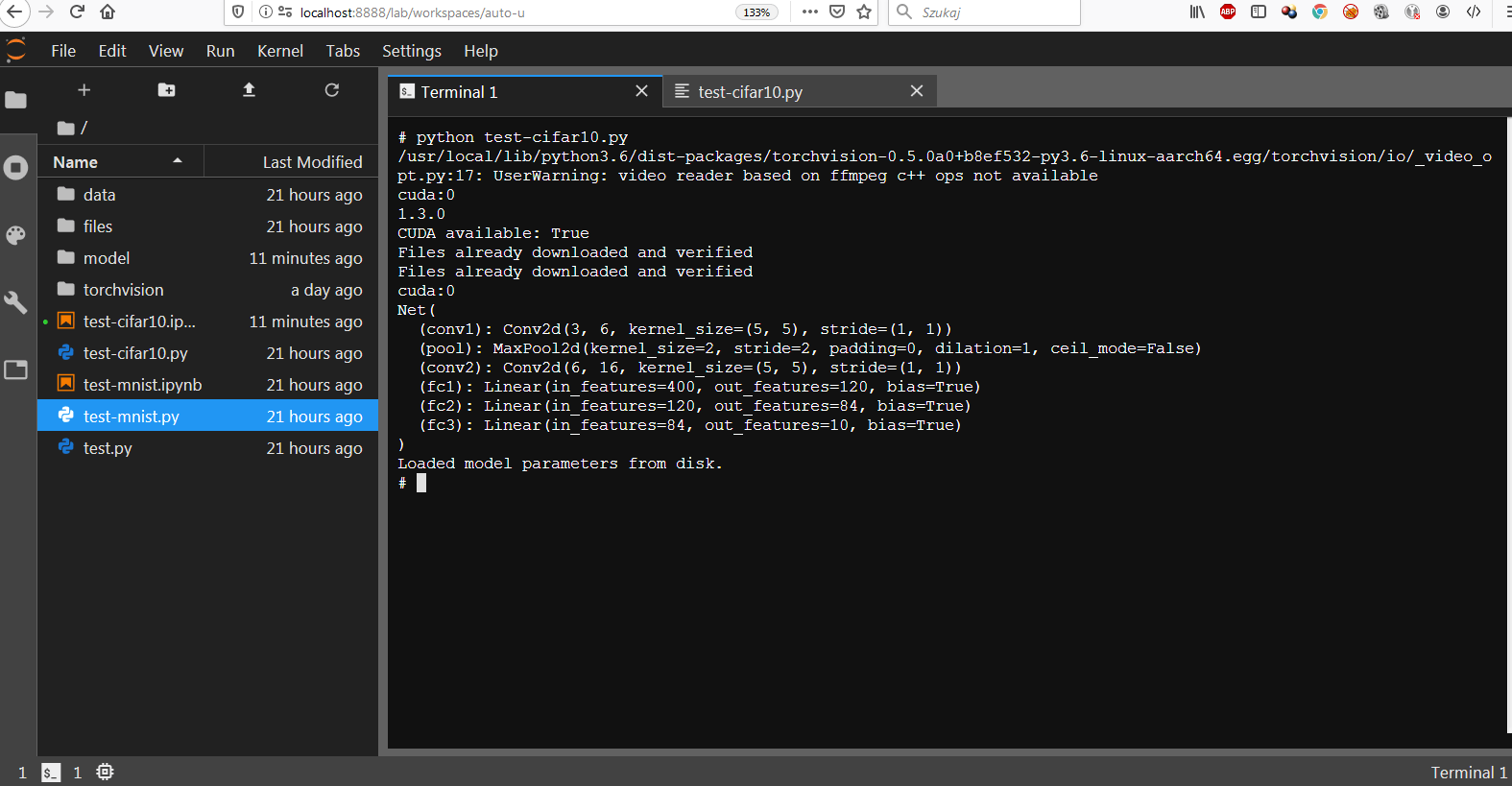
Ważne, żeby podczas trenowania zweryfikować, czy GPU hosta jest wykorzystywane. Warto w tym celu mieć zainstalowany pakiet jtop.
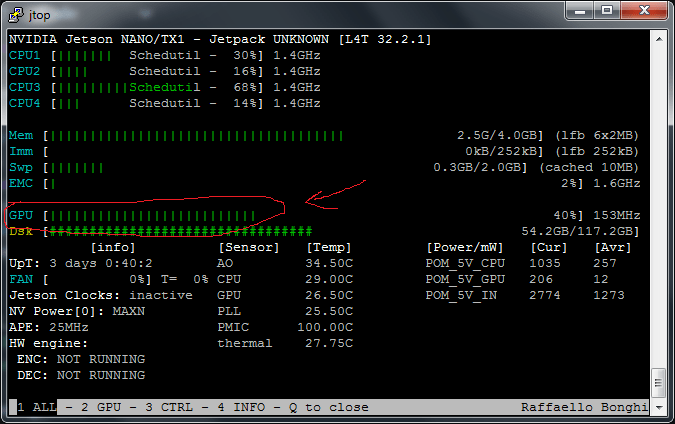
Dla osób, które słyszą po raz pierwszy o pakiecie Pytorch, konkurencyjnym do TenforFlow, zwrócę uwagę na jeden szczegół. Pytorch wymaga jawnego (explicite) oprogramowania wykorzystania CUDA, TensorFlow robi to w trybie niejawnym (implicite).
Przy okazji zwracam uwagę na bazowe oprogramowanie hosta
NVIDIA Jetson NANO/TX1 – Jetpack UNKNOWN [L4T 32.2.1], które jest starsze niż bazowe oprogramowanie wykorzystywane przy budowie obrazów (!).
Można też uruchamiać skrypty Pythona z poziomu wbudowanego terminala
Dla osób, które zamiast Jupyter Lab wolą notatniki, wystarczy w adresie URL zamienić /lab na /tree
Wnioski:
Czy konteneryzacja i uczenie maszynowe mogą się uzupełniać i być efektywnie wykorzystane? Myślę, że tak. Niniejszy wpis jest próbą pokazania i próbą odpowiedzi na pytanie, czy warto znać jedno i drugie? Warto, ale należy pamiętać, że optymalizacja i automatyzacja naszego kodu może dotyczyć nie tylko typowego oprogramowania biznesowego, ale również modeli uczenia maszynowego.
Literatura:
https://ngc.nvidia.com/catalog/containers/nvidia:l4t-base
https://medium.com/@chengweizhang2012/how-to-run-keras-model-on-jetson-nano-in-nvidia-docker-container-b52d0df07129
http://collabnix.com/why-docker-19-03-on-nvidia-jetson-nano/
https://jkjung-avt.github.io/build-tensorflow-2.0.0/
https://github.com/rbonghi/jetson_stats
https://www.howtoforge.com/tutorial/ubuntu-docker-portainer/
mmoskit
Fajny wpis. Do tej pory nie wykorzystywałem konteneryzacji ale może zacznę 🙂
Szara Eminencja
Bardzo ciekawe wykorzystanie konteneryzacji. Znacząco zmniejsza to próg wejścia w Jetson Nano.
Jak przy każdym wpisie duża przejrzystość i jednoznaczność wpisu. Dobry materiał!
djkormo
Ja zrobiłem to w listopadzie 2019, a producent w kwietniu 2020.
https://news.developer.nvidia.com/new-nvidia-jetson-framework-containers-now-available-on-ngc/