
Nieustanny rozwój mocy obliczeniowej komputerów osobistych, fizycznych serwerów i wszelkiej maści maszyn wirtualnych umieszczanych w chmurach prywatnych czy publicznych umożliwił testowanie i uruchamianie modeli uczenia maszynowego, które do niedawna były poza zasięgiem przeciętnego fascynata sztucznej inteligencji. Myślę o osobach, które nie tylko chciały z niej korzystać, ale również wnieść wkład w praktyczne wykorzystanie lat doświadczeń środowiska naukowego. Dotyczy to w szczególności uczenia głębokiego, które jest podzbiorem algorytmów uczenia maszynowego i jedną z jego cech jest pazerność na moc obliczeniową. Głębokie sieci neuronowe składające się z wielu warstw ukrytych i setek tysięcy parametrów (wag), które podczas procesu uczenia są wyznaczane iteracyjne wymagają mocy obliczeniowych. Standardowa jednostka CPU nie radzi sobie odpowiednio skutecznie. Ratunkiem jest wykorzystanie procesorów graficznych GPU, które pozwalają na sprawne przeprowadzanie operacji macierzowych i znacznie przyśpieszają czas obliczeń. Przypomina mi się moje pierwsze uruchomienie takiego modelu z wykorzystaniem laptopa biznesowego i jego 8-rdzeniowego procesora I7 drugiej generacji. Do tego momentu nie miałem świadomości, jakie wydaje dźwięki to obciążone urządzenie. Skończyło się twardym restartem.
W poprzednim wpisie mówiłem o sposobie pracy z płytką Jetson Nano, która jest takim odpowiednikiem Raspberry PI, ale ze sprzętowym procesorem GPU, który może być użyty np. przy wykorzystaniu silnika Tensorflow. Tak opisana konfiguracja jest niejako rozwiązaniem chmury prywatnej serwującym usługę GPU as a Service. WYmaga to oczywiście zakupu urządzenia i jego konfigurację. Powstało pytanie, czy da się zbudować podobne rozwiązanie ale w chmurze publicznej? Takie ,które pozwoli na uruchamianie skryptów języka Python z wykorzystaniem GPU i bez zużycia portfela naszego wewnętrznego Sknerusa.
Okazałą się że jest taka usługa. Usługa Colab firmy Google, pozwala ona między innymi wykorzystać na góra 12h w jednej sesji kartę GPU Nvidia Tesla K-80 . Dla zainteresowanych proponuję poszukać ile jest ona obecnie warta.
Po uruchomieniu mamy do dyspozycji możliwość utworzenia notatnika

Utwórzmy prosty notatnik w języku Python 3, druga wersja tego języka jest nadal obsługiwana, ale pamiętajmy, że jest praktycznie na wymarciu i od 2020 roku nie będzie rozwijana.
Z menu Runtime wybieramy opcję Change Runtime Type
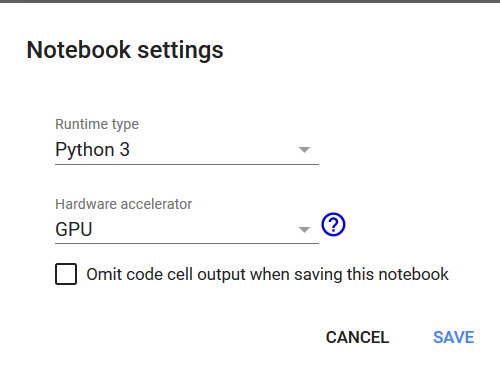
Jest do dyspozycji też procesor TPU, ale o tym opowiem w innym wpisie. Na tę chwilę wybierzmy GPU. Po naciśnięciu przycisku Save w tle zostanie podłączona maszyna wirtualna z gotowym oprogramowaniem. Spójrzmy na chwilę co tu mamy.
W podkatalogu sample_data mamy kilka małych plików z klasycznymi przykładami znanych zbiorów danych.
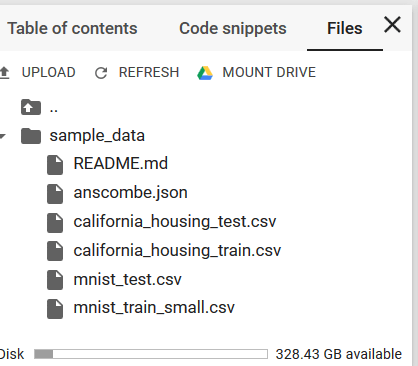
Zwracam uwagę na liczbę na dole. Mamy do dyspozycji ponad 300 GB wolnego miejsca, ale pamiętajmy ze wszelkie dane jaki tam umieścimy są ulotne i po wygaśnięciu sesji 12 godzin nie będziemy mieć do nich dostępu. Na szczęście istnieje możliwość podłączenie Google drive, pobrania danych z zewnętrznych źródeł. Pamiętajmy to tym, oszczędzi nam to na przyszłość wiele rozczarowań. Dla osób, które rozpoczynają przygodę z usługami w chmurach publicznych może się to wydawać na początku ich wadą, ale wbrew pozorom ma to swoje uzasadnienie.
Celem naszego ćwiczenia jest wykorzystanie usługi Colab jako klasycznej maszyny wirtualnej, na której możemy instalować potrzebne nam oprogramowanie, załadować dane do uczenia i załadować skrypty z modelami.
Na początku zobaczmy co mamy tam pod spodem z poziomu notatnika:
!nvidia-smi
!/usr/local/cuda/bin/nvcc --version
To co otrzymujemy na wyjściu to potwierdzenie, że mamy zainstlowane oprogramowanie do obłsugi naszej karty GPU.
Znak ! na początku oznacza wykonanie polecenia powłoki (linux) a nie instrukcji Pythona.
Thu Oct 3 20:13:28 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 430.40 Driver Version: 418.67 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 | | N/A 49C P8 31W / 149W | 0MiB / 11441MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130
Zwracam uwagę, że z pudełka nie mamy zgodności wersji
NVIDIA-SMI 430.40 Driver Version: 418.67 .
Będzie to poprawione w skrypcie wdrażającym oprogramowanie
Zobaczmy czy silnik Tensorflow zauważa urządzenie GPU
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
......
incarnation: 2918730272762479116
physical_device_desc: "device: XLA_GPU device"
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 11330115994
locality {
bus_id: 1
links {
}
}
incarnation: 5961200144614956099
physical_device_desc: "device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7"
]
Urządzenie “/device:GPU:0” jest widoczne jako jedyne tego typu i oznacza to pierwszą kartę GPU (numerujemy od zera). Ogólnie istnieje możliwość korzystania z wielu kart GPU, ale cały czas mówimy tu o darmowym rozwiązaniu, które ma oczywiście swoje ograniczenia, ale nie aż takie, by nie można z niego efektywnie korzystać.
import tensorflow as tf
print("Tensorflow version :",tf.__version__)
Zainstalowana jest wersja 1.14, ale istnieje możliwość instalacji wersji 2.
Tensorflow version : 1.14.0
!uname -m && cat /etc/*release
Jak widać mamy do czynienia z Ubuntu w wersji 18.04 LTS.
x86_64 DISTRIB_ID=Ubuntu DISTRIB_RELEASE=18.04 DISTRIB_CODENAME=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.3 LTS" NAME="Ubuntu" VERSION="18.04.3 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.3 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionic
print ("Hard drive info\n===========================")
!df -H /
print ("RAM info\n===========================")
!free -h
print ( "VM User info\n===========================")
!whoami
Tu jest najważniejsza informacja, zauważmy ze pracujemy na koncie root tej maszyny. Wyższych uprawnień nie można dodać. Nie wiem do końca jaki był zamysł twórcy usługi. Dodatkowo mamy potwierdzenie,że dostępna przestrzeń dyskowa to ponad 300 GB.
Hard drive info
===========================
Filesystem Size Used Avail Use% Mounted on
overlay 385G 33G 333G 9% /
RAM info
===========================
total used free shared buff/cache available
Mem: 12G 713M 9G 2.9M 2.0G 11G
Swap: 0B 0B 0B
VM User info
===========================
rootMożemy jeszcze dowiedzić się o szczegółach informacji o pamięciu, procesorze
!cat /proc/meminfo
!cat /proc/cpuinfo
Pozostawiam to do wykonania dla zainteresowanych.
W tym momencie zaczynamy właściwą instalację oprogramowania.
Kod skryptu umieściłem w repozytorium Github.
!if [ -d "colab-examples" ]; then rm -Rf colab-examples; fi
!git clone https://github.com/djkormo/colab-examples.git
Po pobraniu danych możemy podejrzeć zawartość skryptu
!cat colab-examples/ssh/install.bash
Instalacja oprogramowania sprowadza się do kilku czynności.
1) Aktualizacja repozytoriów Ubuntu
2) Wymuszenie korzystania z Pythona w wersji 3 (Python 3.6.8). Domyślnie jest to wersja 2.7.
3) Instalowane jest oprogramowanie konsolowe do monitoringu o nazwie nvtop
4) Instalacja sterowników Nvidia, tak by zachować zgodność wersji CUDA z wersją oprogramoania aplikacji.
Wybrałem wersje 418.87
Ta część być może nie wygląda zbyt elegancko, ale została przetestowana wielokrotnie.
5) Instalacja oprogramowania Jupyter notebook
#!/bin/bash
alias python='python3'
alias pip='pip3'
sudo apt-get install tmux tree net-tools -y
sudo apt-get install htop
mkdir installs
cd installs
# installing nvtop for nvidia gpu monitoring
git clone https://github.com/Syllo/nvtop.git
mkdir -p nvtop/build && cd nvtop/build
cmake ..
make
make install # You may need sufficient permission for that (root)
cd ..
export LD_PRELOAD=/usr/lib64-nvidia/libnvidia-ml.so
# updating repos for ubuntu
apt-get update
# installing nvidia drivers
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
sudo apt-key add /var/cuda-repo-10-1-local-10.1.243-418.87.00/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda -q
# https://stackoverflow.com/questions/43022843/nvidia-nvml-driver-library-version-mismatch
sudo apt-get --purge remove "*nvidia*" -q
dpkg -l | grep -i nvidia
apt-get update
export LD_PRELOAD=/usr/lib64-nvidia/libnvidia-ml.so
sudo apt install nvidia-driver-418 -q
export LD_PRELOAD=/usr/lib64-nvidia/libnvidia-ml.so
pip install ipykernel
pip install jupyter notebook
Po instalacji oprogramowania, potrzebnego do wykorzystania GPU na tej maszynie (trwa ono około 6 minut) przyszła pora na zmianę konfiguracji sieciowej
!ifconfig -a
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.28.0.2 netmask 255.255.0.0 broadcast 172.28.255.255
ether 02:42:ac:1c:00:02 txqueuelen 0 (Ethernet)
RX packets 71856 bytes 1872302864 (1.8 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 54119 bytes 3771107 (3.7 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Jak widać mamy uruchomioną tylko adresację prywatną 172.16.0.1 – 172.31.255.254
Rozpoczynamy od instalacji usługi SSH
import random, string
password='Pa%%word2019.,'
generate_password=True
if (generate_password):
password = ''.join(random.choice(string.ascii_letters + string.digits) for i in range(30))
#Setup sshd
! apt-get install -qq -o=Dpkg::Use-Pty=0 openssh-server pwgen > /dev/null
#Set root password
! echo root:$password | chpasswd
! mkdir -p /var/run/sshd
! echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
! echo "PasswordAuthentication yes" >> /etc/ssh/sshd_config
! echo "StrictHostKeyChecking no" >> /etc/ssh/sshd_config
print("username: root")
print("password: ", password)
#Run sshd
get_ipython().system_raw('/usr/sbin/sshd -D &')
Przykładowe informacje potrzebne do zalogowanie się do maszyny to para (użytkownik/hasło). W skrypcie umieściłem też statyczne hasło, ale nie jest to polecania konfiguracja, stad generate_password=True i za każdym razie mamy jego inną wartość. Dodatkowo, jeśli dobrze przyjrzymy się skryptowi, to zauważymy, że włączyliśmy możliwość logowania się przez SSH kontem root. Bezpieczeństwo rozwiązania nie jest głównym celem tej demonstracji, ale każda zmiana, która spowoduje tak zwany hardening (utwardzenie), jest mile widziana. Piszcie śmiało.
Na wyjściu skryptu mamy:
username: root password: r79uhC4jXHfHvAIoe7jM1DNrihciln
Tworzymy tunel z maszyny wirtualnej. Wykorzystamy to tego celu darmowe rozwiązanie ngrok.
! wget -q -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
! unzip -qq -n ngrok-stable-linux-amd64.zip
Logujemy się na stronę https://dashboard.ngrok.com/
Pobieramy token
Nie martwcie się, nie skorzystacie z niego, został już dawno przegenerowany.
Zamiast zaglądania na stronę www możemy również z poziomu skryptu podejrzeć numer portu
! curl -s http://localhost:4040/api/tunnels | python3 -c \
"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
Do pełni szczęścia brakuje jeszcze podłączenia z naszego komputera do Colaba.
Wykorzystując popularny klient SSH jakim jest putty logujemy się kontem root na naszą maszynę:
Po zalogowaniu się za pomocą hasła wygenerowanego poprzednio
Potwierdzamy dodanie klucza do naszego lokalnego rejestru i po chwili jesteśmy wewnątrz maszyny Colaba.

Po zalogowaniu się uruchamiamy polecenie
bash /content/colab-examples/ssh/run-tmux-jupyter.bash
I naszym oczom okazuje się konsola podzielona na trzy części
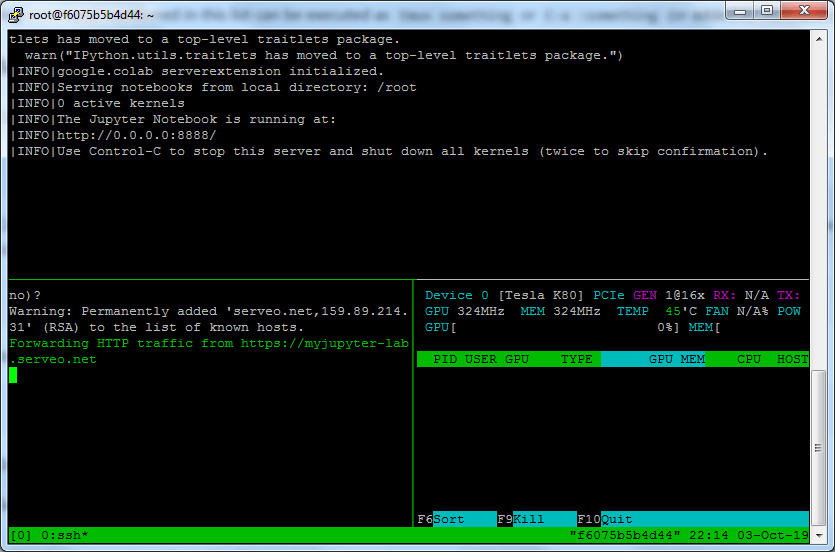
Mamy tu uruchomiony notatnik Jupytera, monitoring GPU i forwardowanie portu 8888 na nazwę publiczną.
myjupyter-lab.serveo.net
Dzięki temu w oknie naszej przeglądarki jest możliwość uruchamiania standardowych notatników Jupytera.

Zawartość pliku bash
#!/bin/bash
# based on https://stackoverflow.com/questions/5609192/how-to-set-up-tmux-so-that-it-starts-up-with-specified-windows-opened
export LD_PRELOAD=/usr/lib64-nvidia/libnvidia-ml.so
tmux new-session -d 'jupyter notebook --ip 0.0.0.0 --NotebookApp.token='' --no-browser'
tmux split-window -v 'ssh -R myjupyter-lab:80:localhost:8888 serveo.net StrictHostKeyChecking=no'
tmux split-window -h 'nvtop'
#tmux new-window 'nvtop'
tmux -2 attach-session -d
Można oczywiście nie korzystać z maszyny w ten sposób. Notatniki Jupytera są dobre do budowy prototypów. Trenowanie modelu może się odbywać w czystych skryptach języka Python. Co więcej, należy zapewnić cykliczną synchronizację danych z Colaba np. na dysk Google. Dotyczy to w szczególności zapisanych modeli i ich wag. Pamiętajmy o czasie jakiego potrzebuje sieć by się trenować. Proces trenowania powinien być przystosowany do wznawiania w dowolnym momencie, ale tak by tracić dane co najwyżej z ostatniej epoki.
Szkic rozwiązania można opisać w poniższy sposób:

Wnioski
Opisana konfiguracja pozwala na wykorzystanie dostępu do darmowego GPU i maszyny wirtualnej z pełną nad nią kontrolą. Dzięki temu nasza podróż w poznawaniu algorytmów uczenia głębokiego przez wykorzystanie np. bibliotek języka Python nie musi być być obarczona dodatkowym kosztem.
Ale nie tylko. W planach mam zamiar zademonstrować, jak wykorzystać Colaba do nauki Apache Sparka.
Literatura
https://imadelhanafi.com/posts/google_colal_server/
https://gist.github.com/yashkumaratri/204755a85977586cebbb58dc971496da
Kody źródłowe
https://github.com/djkormo/colab-examples
Aplikacja do budowy wykresów
mmoskit
Nie dowiedziałem się co prawda w jaki sposób wykorzystać darmową moc obliczeniową GPU do powiększenia zasobów portfela BTC ale artykuł zainspirował mnie do dalszego drążenia tematu 🙂
Tak na poważnie… Dzięki. Dobra Robota!
djkormo
No i się nie dowiesz jak kopać cryptowaluty. Związane jest to z oficjalnym stanowiskiem na stronie
https://research.google.com/colaboratory/faq.html
“Please note that using Colaboratory for cryptocurrency mining is disallowed entirely, and may result in being banned from using Colab altogether.”
Ale pozostałe funckjonalności i uczenie głębokie stoją otworem. Nic tylko brać i wybierać.
Damian
Fajny pomysł i artykuł. Faktycznie czasem ciekawi jak daleko można zajść z publicznymi instancjami maszyn obliczeniowych. A tutaj, dotarłeś w praktyce do samego dna :-D.
Z chęcią przeczytam też jak jak ugryzłeś temat Apache Spark. Oby tak dalej 🙂
djkormo
Poprzedni post dotyczył płytki Jetson Nano, ten opisuje Colaba. Będą kontynuacje w obu kierunkach. Np. Pytorch zamiast pary Keras-TF.